What is Machine Learning? 18 Crucial Concepts in AI, ML, and LLMs


Contents
Dive into Machine Learning (ML), Artificial Intelligence (AI), and Large Language Models (LLMs) to understand the technology behind everyday conveniences.
We simplify complex ideas into accessible insights, perfect for non-technical readers and tech enthusiasts alike.
When your email app sorts spam with pinpoint accuracy or your favorite streaming service predicts what you'll want to watch next, Machine Learning (ML) is at work behind the scenes. Many of us use these technologies daily without realizing the sophisticated processes that power them. These everyday conveniences are just the tip of the iceberg, representing the big impact ML, AI and LLMs have on our lives.
Early attempts at creating intelligent systems, like mining data and building neural networks, faced significant hurdles due to limited computational speed and memory. Today, thanks to advancements in distributed computing, GPU and TPU technology, and high-speed internet, have transformed the field. We now leverage vast datasets from sources like Wikipedia, search engines, and social networks to train Large Language Models (LLMs) for various applications.
While LLMs can sometimes produce inaccurate responses, ongoing efforts by data scientists and engineers are making these models more accurate and reliable. The backbone of modern AI is supported by extensive scientific research, large-scale experiments, open-source frameworks, and sophisticated ML models.
In addition to large language models, smaller language models (SLMs) are gaining traction for their efficiency and targeted applications. These SLMs, while more limited in scope, offer quicker response times and require less computational power, providing an alternative approach to achieving greater accuracy.
In this article, we focus on the machine learning techniques powering today's innovations, without delving into the broader debate on AI's impact. Here, we present the top 18 concepts in ML, AI, and LLMs, offering:
- A general overview for non-technical readers
- Fascinating facts for tech enthusiasts
- Typical usage and popularity
- Noteworthy scientific papers and GitHub projects
- Practical applications for a better future
Understanding artificial intelligence, machine learning, and large language models
Artificial intelligence (AI), machine learning, and large language models are transforming how we interact with technology. Understanding these concepts will help you envision their business applications.
Machine learning is a type of artificial intelligence where computers learn from data and improve over time without explicit programming. It uses algorithms to find patterns, make predictions, and aid decision-making. Examples include recommendation systems, image recognition, and fraud detection.
Artificial intelligence (AI) involves machines mimicking human intelligence processes like learning, reasoning, and self-correction. AI encompasses machine learning, natural language processing, and robotics. It is used in virtual assistants, autonomous vehicles, and data analysis to perform tasks that usually require human intelligence.
Large language models (LLMs) are advanced AI systems designed to understand and generate human language. Trained on massive datasets, these models use deep learning to produce coherent and contextually relevant text. LLMs power applications such as chatbots, translation services, and content creation.

Exploring key concepts in AI, ML, and LLMs
1. Supervised learning
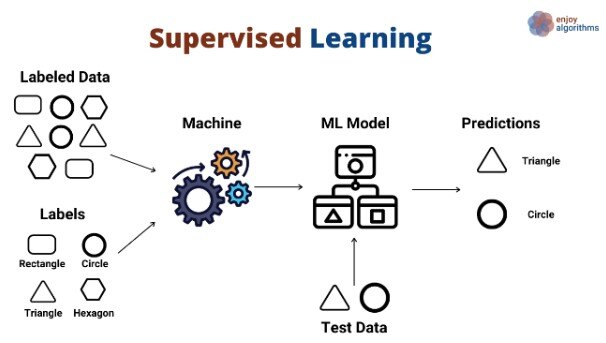
Supervised Learning Scheme,
Source: @metehankozan via medium
Non-technical explanation: Imagine teaching a child to recognize different animals by showing them pictures and labeling them. Supervised learning works similarly, where an algorithm learns from labeled data to make predictions.
Technical explanation: Algorithms like linear regression, support vector machines, and decision trees learn patterns from labeled data to make predictions on new, unseen data.
Practical usage: Spam detection, image classification, fraud detection.
Business value: Wide applicability and ease of implementation.
Future: Supervised learning will remain crucial for tasks requiring accurate predictions based on labeled data, driving advancements in healthcare, finance, and more.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
2. Unsupervised learning
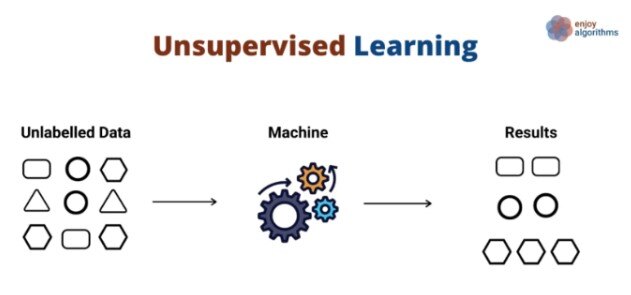 Unsupervised Learning Scheme,
Unsupervised Learning Scheme,
Source: @metehankozan via medium
Non-technical explanation: Imagine a child grouping toys based on their similarities without being told what to do. Unsupervised learning works similarly, where algorithms discover patterns and structures in unlabeled data.
Technical explanation: Techniques like clustering, dimensionality reduction, and association rule mining are used to uncover hidden relationships and insights from unlabeled data.
Usage: Customer segmentation, anomaly detection, recommendation systems.
Business value: It allows for the exploration of complex datasets without manual labeling.
Future: Unsupervised learning will play a vital role in understanding complex data, leading to breakthroughs in personalized medicine, scientific discovery, and more.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
3. Reinforcement learning
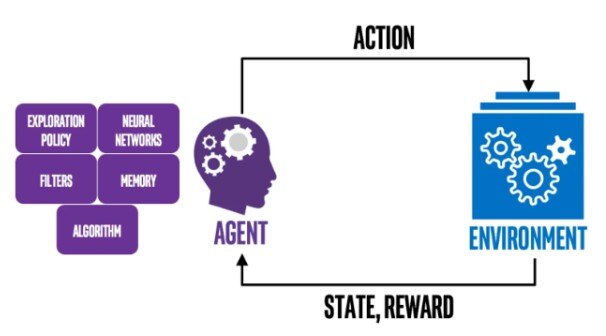
Reinforcement learning schema,
Source: intellabs
Non-technical explanation: Imagine teaching a dog a new trick by rewarding it for desired behavior. Reinforcement learning is similar, where an agent learns through trial and error, receiving rewards for positive actions and penalties for negative ones.
Technical explanation: Algorithms like Q-learning and Deep Q-learning are used to train agents to optimize their actions in a dynamic environment.
Usage: Game playing (AlphaGo, AlphaZero), robotics, autonomous driving.
Business value: It allows to solve complex problems in dynamic environments.
Future: Reinforcement learning will revolutionize automation, enabling robots and AI systems to learn and adapt in real-world scenarios, leading to safer and more efficient solutions.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
|
4. Deep learning
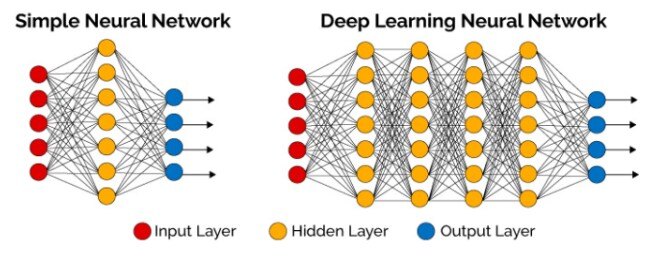
Simple Neural Network vs Deep Learning Neural Network,
Source: thedatascientist.com
Non-technical explanation: Imagine a computer learning to recognize objects in images like a human brain does. Deep learning uses artificial neural networks with multiple layers to learn complex patterns from data.
Technical explanation: Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs) are powerful deep learning architectures.
Usage: Image recognition, natural language processing, speech recognition.
Business value: Enable to achieve state-of-the-art results in various domains. LLMs like ChatGPT, LLAMA, Gemini, and Groq assist billions of people.
Future: Deep learning will continue to drive advancements in AI, enabling machines to understand and interact with the world in increasingly sophisticated ways.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
5. Natural language processing (NLP)
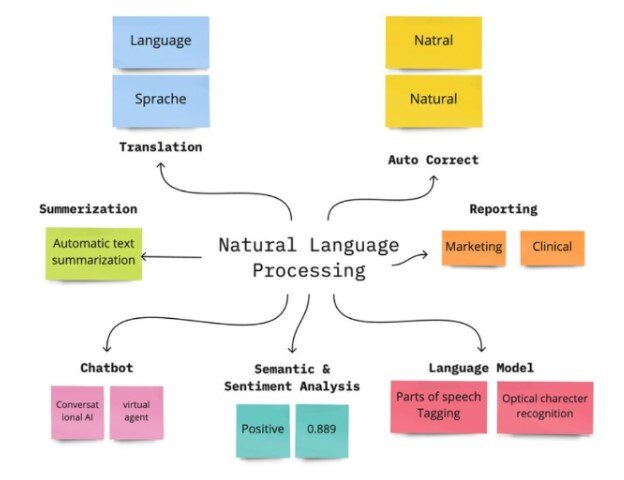
Natural Language Processing,
Source: researchgate.net
Non-technical explanation: Imagine a computer understanding and responding to human language like a real person. Natural Language Processing (NLP) focuses on enabling computers to process and understand human language.
Technical explanation: Techniques like text classification, sentiment analysis, machine translation, and language modeling are used to analyze and generate human language.
Usage:
- Chatbots
- Machine translation
- Text summarization
- Sentiment analysis
Business value: With the increasing amount of text data available NLP enabling enhanced accuracy, broader applications, improved insights, and scalability.
Future: NLP will revolutionize communication, enabling seamless interaction between humans and machines and leading to more efficient and personalized experiences.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
6. Computer vision
%20example.jpg?width=615&height=327&name=Segment%20Anything%20Model%20(SAM)%20example.jpg)
Segment Anything Model (SAM) example
Source: appen.com
Non-technical explanation: Imagine a computer seeing and understanding images like a human eye. Computer vision focuses on enabling computers to "see" and interpret visual information.
Technical explanation: Techniques like image classification, object detection, and image segmentation are used to analyze and understand images.
Usage:
- Self-driving cars
- Medical imaging
- Facial recognition
Popularity: Computer vision is extremely popular due to its wide range of applications and the availability of large image datasets.
Future: Computer vision will transform industries like healthcare, transportation, and security, enabling machines to perceive and interact with the world in new ways.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
|
7. Generative adversarial networks (GANs)

Goodfellow experiment with generating images using GAN
Source: IBM
Non-technical explanation: Imagine a computer creating realistic images or videos that look like they were made by a human. Generative Adversarial Networks (GANs) are a type of deep learning model that can generate new data that resembles the training data.
Technical explanation: GANs consist of two neural networks: a generator that creates new data and a discriminator that tries to distinguish between real and generated data.
Usage:
- Image generation
- Video generation
- Data augmentation
Business value: GAN creates high-quality synthetic data.
Future: GANs will transform content creation, enabling the generation of realistic and creative content for various applications, from art to scientific research.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
8. Transfer learning
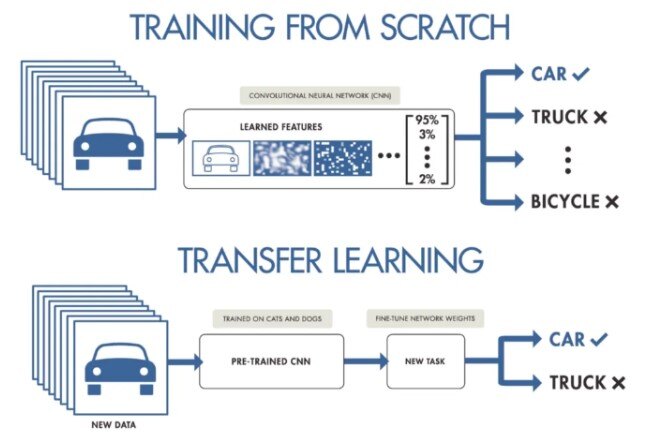
Transfer Learning,
Source: DataDrivenInvestor
Non-technical explanation: Imagine a student learning a new subject by applying knowledge from previous courses. Transfer learning allows machine learning models to leverage knowledge from one task to improve performance on another related task.
Technical explanation: Pre-trained models are fine-tuned on new datasets to adapt to specific tasks, reducing training time and improving accuracy.
Usage:
- Image classification
- Natural language processing
- Object detection
Business value: Efficient in solving complex problems.
Future: Transfer learning will accelerate AI development, enabling faster and more efficient solutions for various tasks, and leading to wider adoption and impact.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
|
9. Explainable AI (XAI)
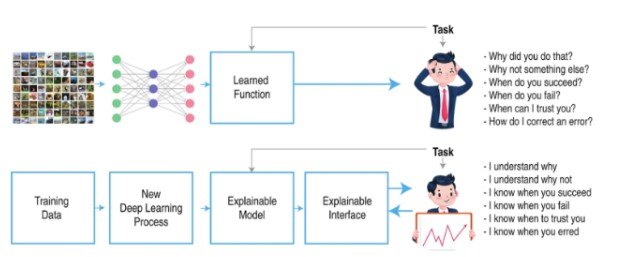
Explanation framework
Source: DeepViz
Non-technical explanation: Imagine a computer explaining its decisions in a way that humans can understand. Explainable AI (XAI) focuses on making AI models more transparent and interpretable.
Technical explanation: Techniques like feature importance analysis, decision tree visualization, and attention mechanisms are used to understand the reasoning behind AI predictions.
Usage:
- Healthcare: Accelerates diagnostics, image analysis, resource optimization, and medical diagnosis.
- Finance: Speeds up credit risk assessment, wealth management, and financial crime risk assessments.
- Legal: Accelerates resolutions using explainable AI in DNA analysis, prison population analysis, and crime forecasting where transparency and accountability are crucial.
Business value: It enhances trust in AI systems by providing transparency and interpretability, allowing users to understand how decisions are made.
Future: XAI will foster trust and acceptance of AI, enabling its responsible and ethical deployment in critical domains, promoting fairness and accountability.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
10. Reinforcement learning with deep learning (Deep RL)
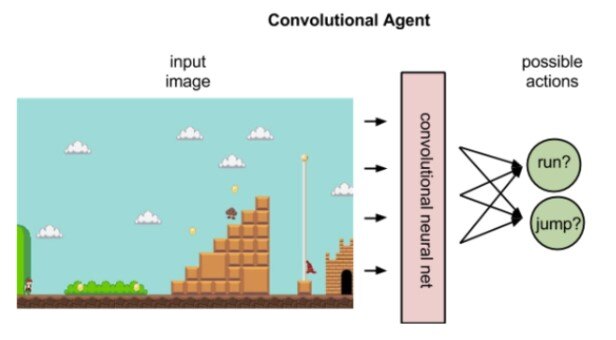
Convolutional Agent
Source: shivam5
Non-technical explanation: Imagine a computer learning to play a complex game like chess or Go by itself, improving its strategy through experience. Deep reinforcement learning (Deep RL) combines the power of reinforcement learning with deep learning to solve complex problems.
Technical explanation: Deep neural networks are used to represent the value function and policy function in reinforcement learning, enabling agents to learn from high-dimensional data.
Usage:
- Game playing (AlphaGo, AlphaZero)
- Robotics
- Autonomous driving
Popularity: Deep RL is increasing rapidly in popularity due to its ability to achieve superhuman performance in complex tasks.
Future: Deep RL will enhance automation, enabling robots and AI systems to learn and adapt in real-world scenarios, leading to safer and more efficient solutions.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
11. Federated learning
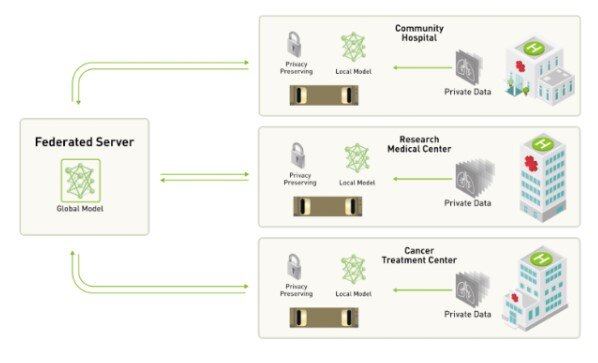
A centralized-server approach to federated learning
Source: NVIDIA
Non-technical explanation: Imagine a group of people collaborating to learn a new skill without sharing their personal data. Federated learning allows machine learning models to be trained on decentralized data without compromising privacy.
Technical explanation: Models are trained on individual devices and then aggregated to create a global model, preserving data privacy.
Usage:
- Healthcare
- Mobile devices
- Financial institutions
Business value: Addresses privacy concerns in AI development, ensuring data security and compliance.
Future: Federated learning will enable the development of machine learning models that respect user privacy, leading to more ethical and responsible AI applications.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
12. Bayesian deep learning
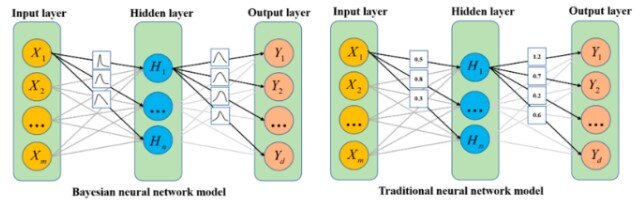
Comparison of BNN model and traditional neural network model structure
Source: MDPI
Non-technical explanation: Imagine a computer learning from uncertainty and incorporating prior knowledge into its decisions. Bayesian deep learning combines the power of deep learning with Bayesian statistics to handle uncertainty and incorporate prior knowledge.
Technical explanation: Bayesian methods are used to estimate the parameters of deep neural networks, providing uncertainty estimates for predictions.
Usage:
- Medical diagnosis
- Financial forecasting
- Scientific discovery
Business value: Handle uncertainty and provide more reliable predictions, enhancing decision-making and risk management.
Future: Bayesian deep learning will enable more robust and reliable AI systems, leading to better decision-making in critical domains like healthcare and finance.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
13. Graph neural networks (GNNs)
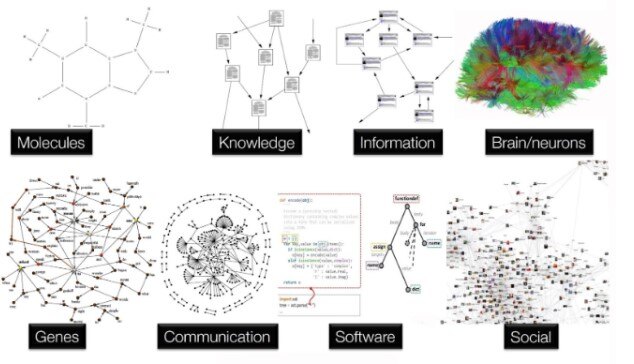
Knowledge from many fields of science and industry can be expressed as graphs
Source: NVIDIA
Non-technical explanation: Imagine a computer understanding relationships between objects like a social network. Graph Neural Networks (GNNs) are a type of deep learning model designed to process and learn from graph-structured data.
Technical explanation: GNNs use message-passing mechanisms to propagate information between nodes in a graph, capturing complex relationships and patterns.
Usage:
- Social network analysis
- Drug discovery
- Recommendation systems
Business value: Handle complex relationships and patterns in graph data.
Future: GNNs will revolutionize our understanding of complex systems, enabling breakthroughs in fields like social science, biology, and materials science.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
|
14. Multi-agent reinforcement learning (MARL)
Autonomous smart car system
Source: jcomp
Non-technical explanation: Imagine a group of robots collaborating to solve a complex task, learning from each other's experiences. Multi-Agent Reinforcement Learning (MARL) extends reinforcement learning to multiple agents that interact and learn in a shared environment.
Technical explanation: Agents learn to coordinate their actions and optimize their collective performance in a multi-agent setting.
Usage:
- Robotics
- Autonomous driving
- Traffic control
Business value: Solve complex problems involving multiple interacting agents.
Future: MARL will enable the development of intelligent systems that can collaborate and solve complex problems in real-world scenarios, leading to advancements in robotics, transportation, and more.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
15. Automated Machine Learning (AutoML)
.jpg?width=626&height=340&name=Multi-agent%20reinforcement%20learning%20(MARL).jpg)
AutoML schema,
Source: EDUCBA
Non-technical explanation: Imagine a computer automatically designing and optimizing machine learning models without human intervention. Automated Machine Learning (AutoML) aims to automate the process of machine learning model development.
Technical explanation: Techniques like hyperparameter optimization, model selection, and feature engineering are automated to optimize model performance.
Usage:
- Data scientists
- Developers
- Businesses looking to streamline machine learning workflows
Business value: Democratize machine learning by automating complex processes, making advanced analytics accessible to a wider audience.
Future: AutoML will empower non-experts to leverage the power of machine learning, leading to wider adoption and innovation across various domains.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
16. Large language model (LLM)
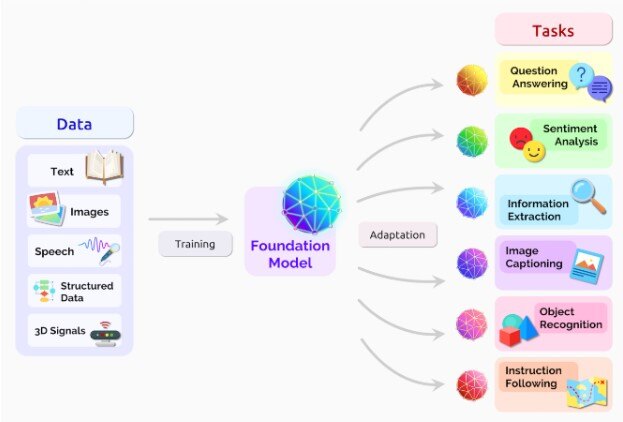
Large Language Model - Inequity and fairness
Source: Center for Research on Foundation Models (CRFM), a center at
Non-technical explanation: Large Language Models (LLMs) are trained on massive amounts of data and use sophisticated algorithms to excel in understanding and generating human-like language. As a result, they can perform various tasks such as text generation, completion, translation, sentiment analysis, and summarization. Both humans and automatic agents can interact with LLM models using dedicated prompts. While not quite "AI," LLMs represent a significant step towards advanced language understanding.
Technical explanation: An LLM is a type of machine learning model that can recognize and generate text, among other tasks. LLMs are built on a type of neural network called a transformer model. These models generate predictions of tokens, resulting in coherent sentences and logical responses.
Usage:
- Generative AI
- Text and article generation
- Image generation
- Video generation
- Summarization
- Agent systems with LLM support
Business value: LLMs are rapidly gaining traction for their application in chatbots, virtual assistants, and other systems that facilitate machine-human cooperation.
Future: LLMs are gaining trust and becoming foundational for various IT solutions. Agent systems supported by LLMs are particularly promising for distributed and complex production environments.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
17. Machine learning for time series data
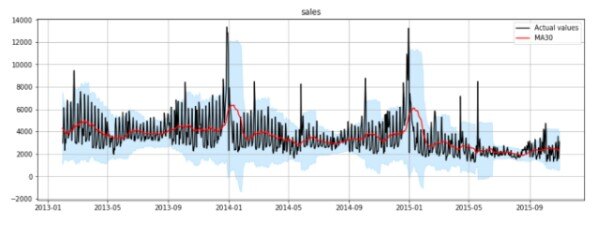
Source: Towards Data Science
Non-technical explanation: Imagine a computer predicting future trends based on historical data, like stock prices or weather patterns. Machine learning for time series data focuses on analyzing and predicting patterns in sequential data.
Technical explanation: Techniques like ARIMA models, recurrent neural networks (RNNs), and long short-term memory (LSTM) networks are used to model time series data.
Usage:
- Financial forecasting
- Weather prediction
- Anomaly detection
- Manufacturing maintenance
Popularity: Accurate forecasting and trend analysis due to the large volume of available time series data.
Future: Machine learning for time series data will revolutionize forecasting and decision-making in various domains, leading to more accurate predictions and better outcomes.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
|
18. Machine learning for robotics (MLR)
.jpg?width=640&height=192&name=Machine%20learning%20for%20robotics%20(MLR).jpg)
Source: xbpeng.github.io
Non-technical explanation: Imagine robots learning to perform complex tasks like assembling products or navigating complex environments. Machine Learning for Robotics (MLR) focuses on using machine learning to improve the capabilities of robots.
Technical explanation: Techniques like reinforcement learning, deep learning, and computer vision are used to train robots to perform tasks and adapt to new environments.
Usage:
- Manufacturing
- Logistics
- Healthcare
- Exploration
Business value: Can perform complex tasks autonomously.
Future: MLR will revolutionize robotics, enabling robots to perform tasks that are currently impossible or dangerous for humans, leading to increased efficiency and safety in various industries.
|
Resource type |
Link |
|
Papers |
|
|
Repositories |
The transformative potential of machine learning, artificial intelligence, and large language models
This comprehensive exploration of 18 key concepts in machine learning (ML), artificial intelligence (AI), and large language models (LLMs) showcases the potential of these technologies. Each concept, from reinforcement learning and computer vision to federated learning and explainable AI, plays a crucial role in advancing our understanding and application of AI.
These technologies are reshaping the business landscape by automating complex tasks, improving decision-making, and enhancing human-machine collaboration.
Looking to the future, the collaboration between humans and intelligent systems will become even more integral. As AI continues to evolve, its role in enhancing efficiency, safety, and innovation across various sectors will expand.
For those interested in diving deeper, we recommend exploring the linked open-source repositories and articles. These resources provide valuable insights and practical applications of the discussed concepts.





