Responsive System With AWS Aurora and a Ruby Application

Contents
In this post, I will walk you through how we met a client's demands of higher network traffic with the AWS Aurora service, together with a step-by-step journey of fitting it into the existing infrastructure setup.
First things first...
Let me briefly describe the background and where we were at before I go into the actual plan of elevating our infrastructure to the next level. For the sake of simplicity, I will skip all unrelated system parts, like caches, queues, or application tiers, which are irrelevant to the upgrade.
That being said, the system was pretty straightforward. The components which comprise the architecture are:
- RDS PostgreSQL;
- A fleet of static EC2s that served the Ruby on Rails (RoR) application;
- Application Load Balancer;
- CloudWatch;
Following the famous quote "one picture says more than a thousand words," the below diagram represents the original design of the system.

As you can see, it is a very popular three-tier architecture with the presentation layer as the client's mobile app, application layer as our RoR application and the data layer with and RDS PostgreSQL database. Such design perfectly fits our application, but the incoming traffic was limited to the computation power of EC2 machines and RDS.
The Challenge
Since the digital market grows and everyone, especially during coronavirus season, utilizes Internet services like crazy, the client decided to popularize their service and attract more users, which obviously should significantly increase the traffic on the application side. The requirement was clear - "Handle peaks of 2.5k simultaneous active users without any service disruption". So that's what we did.
The Plan
We had to plan our new infrastructure according to the demand, however first we performed performance tests of the current setup to get a point of reference and check the actual bottlenecks.
The first tests showed 2 things:
- The current setup can handle 4.5k requests/min, which is far away from what we would like to achieve.
- After a few minutes timeouts (504 HTTP errors) started to appear on the Load Balancer

Obviously, the small amount of application EC2s was a bottleneck due to which we were unable to finish client requests in 10 seconds. With this information, the next step was pretty clear - increase the number of EC2s. To avoid unnecessary costs, the only reasonable approach was to use an auto-scaling mechanism.
Going back to the original infrastructure - all the components were static and did not scale at all. Fortunately, our application was 12-factor consistent, so scaling-out was almost out-of-the-box. With the AWS autoscaling mechanism in place, it was a matter of minutes to spawn machines dynamically based on the CPUUtilization metric.
The next round of tests bring us to the following picture:

As you can see, with more computation power the amount of requests looks much better now, but we are still struggling with timeouts. We checked the logs from the application and saw many messages like these:
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
So that's the problem. It looks like the database has crashed under heavy load and that's why we were still receiving timeouts on the application side. In order to handle such traffic peaks, we had to increase database throughput. By increasing the flavor of DB instance, we would increase costs permanently, but since we needed only to handle peaks, we had to find some more scalable solution - and this is where Amazon Aurora comes into the play.
The Journey
At this point, we decided to adopt the Amazon Aurora solution to scale our data-tier in a cost-efficient way. Amazon Aurora is a fully managed relational database engine that enables database scalability through adding read-replicas automatically based on embedded metrics like CPUUtilization or DatabaseConnections. This brief video contains everything you need for the purpose of this article:
Aurora, of course, provides many other cool features like incremental backups or storage autoscaling. However, this could be a separate article dedicated to Aurora. If you sense you would like to explore Aurora more feel free to visit the official Amazon Aurora documentation
After migrating from RDS to Aurora (the process is well documented here) our infrastructure architecture looks as follows:
-png.png)
Please notice that there are actually two Aurora endpoints. One for WRITES and another one for READS - it is a consequence of read-replicas' scalability. A load balancer within the Aurora Cluster distributes READS among read-replicas via round-robin DNS. This part is crucial to understand, since the application has to be aware of these two endpoints in order to choose an appropriate DB instance according to SQL query type. For that purpose, we used the makara Ruby gem in our application which allows us to explicitly point to READ and WRITE database endpoints.
With such scalable infrastructure on each tier level there should be no more bottlenecks, right? Wrong!
The following challenge appeared during the next set of performance tests:

As you can see the Aurora read-replicas scaled up under heavy use of CPU, but there are no connections on the new scaled-out read-replica. So what's going on? It turns out the application keeps a TCP connection (session) to the previous read-replica and only a few connections come from freshly started applications during the EC2 autoscaling process. This problem can be resolved in two ways:
- Scale read-replicas faster to bring more connections from newly started EC2 instances.
- Prevent the creation of long-lived TCP sessions and keep them short-lived.
The first solution is naive and amounts to asking for problems since it is almost impossible to synchronize the scaling of a fleet of EC2 instances with read-replicas. The second one sounds pretty good, but we have to find a mechanism that will tear down the long-living TCP sessions after a specific time. How specific depends on your system and requirements. For example, allowing connections to live for no longer than 10 minutes means that about 10 minutes after the second read-replica will be online the load should be back to being balanced.
After digging through many settings within the makara gem and ActiveRecord, which we use as an ORM and for connection pooling (which we will discuss in the next part of the article), we have finally found two essential parameters inside ActiveRecord:
idle_timeout- number of seconds that a connection will be kept unused in the pool before it is automatically disconnected (default 300 seconds).reaping_frequency- frequency in seconds to periodically run the Reaper, which attempts to find and recover connections from dead threads, which can occur if a programmer forgets to close a connection at the end of a thread or a thread dies unexpectedly.
This is specific for Ruby on Rails applications however here you can find useful DB connection parameters for other programming languages.
We set each of those to 5 seconds and tried again with performance tests.

Disaster Recovery
Such a setup was good enough to handle requested traffic with an autoscaling mechanism, but we wanted to be sure that our system will handle all these users even when a part of it breaks. The application tier has already been covered with a Disaster Recovery plan since each broken instance of the app can be easily and automatically replaced within the autoscaling group. The more interesting part was the data tier. To simulate a crash of one of the DB instances, we used Amazon's embedded failover mechanism. Unfortunately, after failover the application still maintained the TCP sessions even with the reaping_frequency setting enabled. This led to plenty of application instances with a lot of open TCP sessions which were unused and filled up the connection pool, which causes timeouts on the client side.
Sidenote: To keep this story reasonably short, please refer to the following stories, where others bumped into the similar problem:
This was unacceptable, so after some debugging we decided to abandon the makara gem and decouple connection pooling to third-party middle-ware software.
Connection pooling
Before we move on to the middle-ware software section we have to understand what connection pooling actually is and why it is so important.
You can get an outstanding knowledge about connection pools from the article, but in order to keep it short I will just extract here a quote just to paste a quote to let you understand what we are talking about:
A pool is an object that maintains a set of connections internally, without allowing direct access or usage. These connections are given out by the pool when communication with the database needs to happen, and returned to the pool when the communication is finished. The pool may be initialized with a configured number of connections, or it may be filled up lazily on-demand. The ideal usage of a connection pool would be that code requests a connection from the pool (called a checkout) just when it needs to use it, uses it, and puts it back in the pool (a release) immediately. This way, the code is not holding on to the connection while all the other non-connection related work is being done, greatly increasing efficiency. This allows many pieces of work to be done using one or a few connections. If all the connections in a pool are in use when a new checkout is requested, the requester will usually be made to wait (will block) until a connection has been released.
PostgreSQL middle-ware
Since our system became more complex and the application didn't handle DB failover we decided to decouple connection pooling to third-party software. There are two popular proxies dedicated to PostgreSQL:
These systems allow you to make as many database connections as you want without worrying about management because the connections they give you are cheap simulated connections that they handle with low overhead. When you attempt to use one of these simulated connections, they pull out a real connection from an internal pool and map your fake connection onto a real one. After the proxy sees that you've finished using the connection, it keeps your fake connection open, but aggressively releases and re-uses the real connection. The connection counts and release-aggressiveness settings are configurable and help you tune for a gotchas like transactions, prepared statements, and locks.
For a scalable Amazon Aurora database, only PgPool fits well since PgBouncer does not support READ/WRITE SQL query split. The configuration of PgPool can be overwhelming at the beginning, but there is a set of settings dedicated for Aurora that can be a good starting point. It's especially worth focusing on the num_init_children and max_pool parameters which state how many connections can be opened to a database. More information about the relationship between parameters and how to set them accordingly to your need can be found here.
After some configuration tuning and a couple more performance tests we finally managed to achieve the goal:
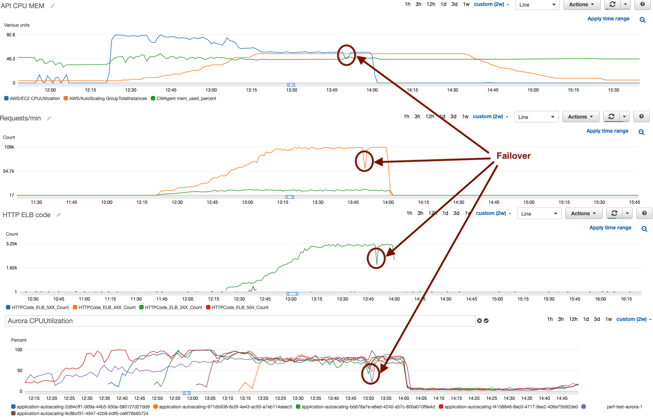
As you can see, connections are spread evenly to the replicas and during failover sessions from failed instances are released and switched to other replicas instantaneously.
Conclusion
After a few twists and turns, we landed with bullet-proof scalable infrastructure with resilience on DB and application levels. The system will handle even more than 2.5k simultaneous users in a cost-efficient way since it can scale out automatically based on the system load. This journey description was intended to present a real-life example of how infrastructure system can be designed and improved with all the ups and downs in the middle.
This story is not over yet, since there is much more we can adjust, like replica lag for example. So I would like to leave you with a quote which I think this posts illustrates:
It is not how it ends that matters, but the journey it takes to get there.
Photo by Taylor Vick on Unsplash





