4 Best Practices for Reliable Azure Architecture


Contents
Building a reliable, scalable Azure architecture requires planning and forethought. By following these best practices, your Azure cloud computing environment will meet your needs now and into the future.
Whether you’re just starting out or have been using Azure for a while, these tips will help you get the most from your cloud investment.
Reliable Microsoft Azure architecture has the possibility to recover from failures at any scale and ensure that workloads of your cloud apps are available. This architecture reliability differs for on-premise and cloud environments. For example, for on-premise you need to provide better equipment and ensure power supply to achieve better reliability.
Robust and trustworthy Azure architecture is key to successful cloud deployments when Microsoft cloud is your environment. In this post, we'll explore four best practices to make your architecture as reliable as possible.
These practices include proper disaster recovery plans, building a multi-region architecture, monitoring, and leveraging the potential of a good design. Follow these tips, and you can be confident that your Azure deployment will meet your needs.
Why should you build your architecture on Azure?
Cloud architecture must be designed to expect occasional failures and recover from them. Azure, as one of the main cloud providers, has many resiliency features already built into the cloud platform. Azure Architecture Center may also come in handy. Some services have built-in resilience:
- Microsoft Azure Storage, SQL Database, and Cosmos DB all provide built-in data replication across availability zones and regions.
- Azure managed disks are automatically placed in different storage scale units to limit the effects of hardware failures.
- Virtual machines (VMs) grouped in an availability set are spread across several fault domains. A fault domain is a group of VMs that share a common power source and network switch. Spreading VMs across fault domains limits the impact of physical hardware failures, network outages, or power interruptions.
- Availability Zones are physically separate locations within each Azure region. Each zone is composed of one or more data centers equipped with independent power, cooling, and networking infrastructure. With availability zones, you can design and operate applications and databases that automatically transition between zones without interruption. This ensures resiliency if one zone is affected. For more information, you can reference Regions and Availability Zones in Azure.
In 2018, Azure reported 99.995% of average availability for all to compute services across the global cloud infrastructure.
Most Azure regions are paired with another region within the same geographic area to make a regional pair (or paired regions). Regional pairs help you to support the always-on availability of Azure resources used by your infrastructure. The following topics describe some prominent characteristics of paired regions:
- Physical isolation. Azure prefers at least 300 miles of separation between multiple data centers in a regional pair. This principle isn't practical or possible in all geographic areas. Physical data center separation reduces the likelihood of natural disasters, civil unrest, power outages, or physical network outages affecting both regions at once.
- Platform-provided replication. Some services like Geo-Redundant Storage provide automatic replication to the paired region.
- Region recovery order. During a broad outage, recovery of one region is prioritized out of every pair. Applications that are deployed across paired regions are guaranteed to have one of the regions recovered with priority.
- Sequential updates. Planned Azure system updates are rolled out to paired regions sequentially (not at the same time). Rolling updates minimizes downtime as well as reduces bugs and logical failures in the rare event of a bad update.
- Data residency. Regions reside within the same geographic area as their enabled set (except for the Brazil South and Singapore regions).
Is it enough?
In modern applications, we expect 100% availability, without any downtime or interruption. Even Azure info structure can fail, which is why we still needed to build resilience in your application. It can be done on each level of architecture.
Azure architecture tips and insights
Microsoft Azure architecture is a complex and ever-evolving topic. Below you'll find a few best practices and tips you should consider at all times while working with Microsoft cloud. They can help you navigate the Azure landscape and gain insights from those who have experience working with the Azure platform.
Disaster recovery plan
A disaster recovery plan is a document which describes what needs to be done after an unplanned incident to continue work as fast as possible.
It's important not only to create such a plan but also go through all the steps a few times to understand how much time is required for each step and what possible problems you might need to face during the recovery process.
For example: The recovery process of a project revealed that VM with Linux OS had a new version of the kernel which wasn’t supported by extensions installed on it. Microsoft didn’t offer a fast resolution, so as a work-around, we decided to manually downgrade the kernel version of the Linux machine.
If the issue had happened during the failure of a production environment, it could have taken 4-6 hours for the team to resolve it. With this knowledge, however, they were able to avoid such a massive waste of time.
Multi-region architecture
Azure's multi-region architecture helps us to ensure availability of Azure services and data, even in the event of an Azure region failure. The regions are physically isolated from each other, and each one has its own power grid, cooling, and networking infrastructure.
There are also Azure Region Pairs, i.e. groups of Azure regions that are located in different Azure geolocations.
In this example, we have two regions – the primary and secondary ones. In the event of failure in one region, the other one will be available. This architecture is mainly available for large applications. For small ones that don’t need such a complex architecture, this method is not applicable.
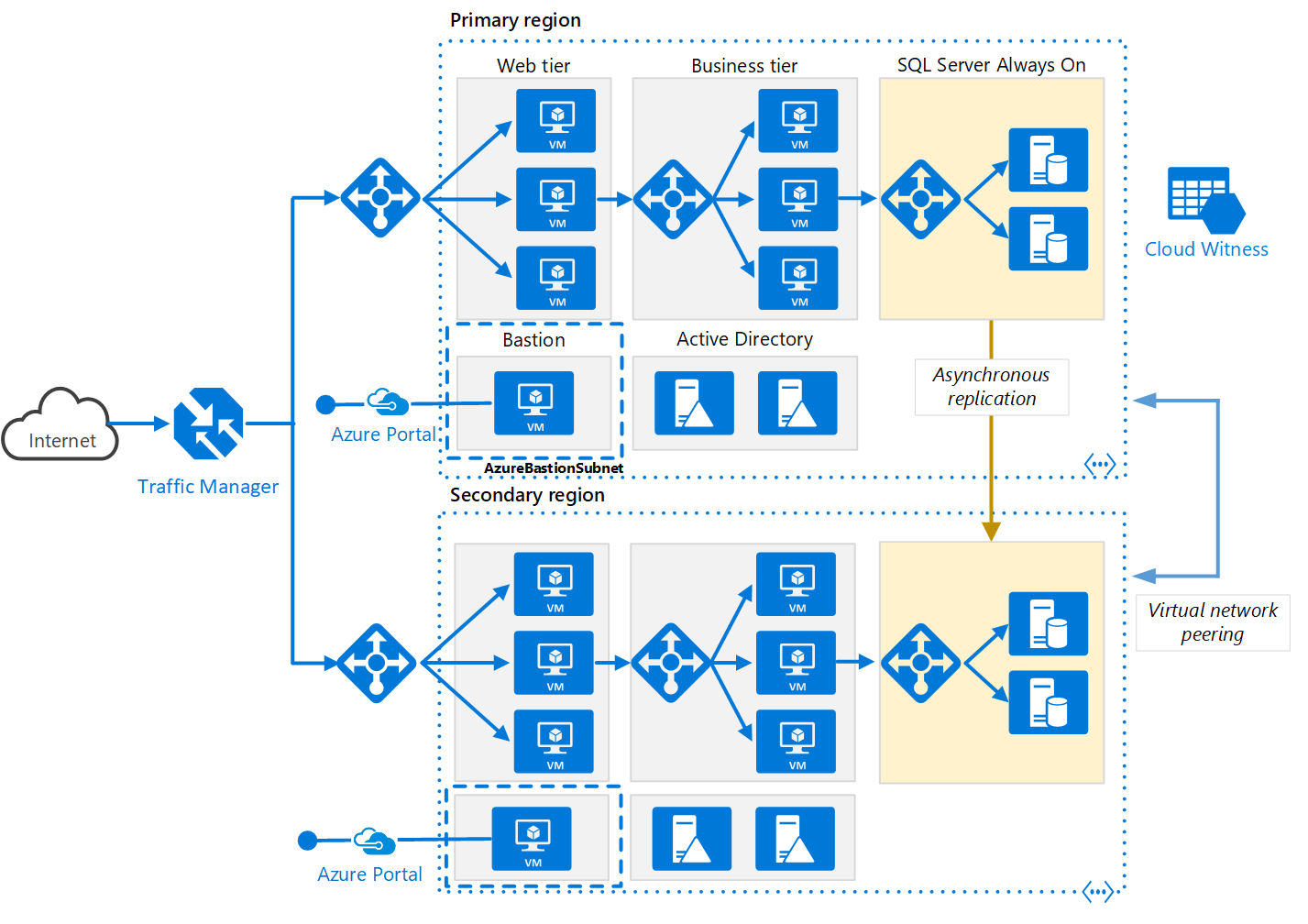
Here are several useful tips for multi-region architecture:
- Use at least two Azure regions
- For the production environment, use at least two application gateways
- Note that using NSG rules restricts traffic between tiers
Monitoring
Monitoring is one of the most important methods to collect information on the health of your architecture. Importantly, it's possible to find issues before customers will report them, and fix them.
You can set up Azure alerts for the most important part of your architecture. For example: an alert rule for Application Gateway.

In case of more than 10 failed requests, alerts will execute an action group for this Application Gateway.
One of the good practices is to always check the Azure availability page before implementing significant changes in your infrastructure to avoid possible failures with it.

Azure architecture design tips
When designing a cloud-based solution on Microsoft Azure, there are a few things to keep in mind in order to ensure that your application is performant, scalable, and secure:
- You should know your availability target and recovery target of each component of your architecture to build it right. Availability target represents a commitment around performance and availability of the application. Recovery target identifies how long the workload can be unavailable and how much data it is acceptable to lose during a disaster.
- Ensure the application & data platforms meet your reliability requirements
- Ensure connectivity. It can be achieved by such Azure services as: global load-balancer (to distribute traffic and failover actress regions) and ExpressRoute or VPN (to ensure redundant connections from different locations).
- Eliminate single point of failure
- Design resilience to respond to outages. Architecture should be designed to allow for impeccable work even if regional or zonal services are affected. Having said that, it may come with reduced functionality or degraded performance.
- Perform a failure mode analysis. This analysis will help you identify the type of failure your application might experience, impact of each failure, and possible recovery strategies.
- Design for scalability. Architecture should be designed in a way which would enable you to scale the system every step of the way.
Azure architecture reliability starts before development
By planning your Azure architecture reliability up front, you can save time and money down the road. Creating a reliable infrastructure for cloud computing requires good understanding of your system's weaknesses and addressing them head-on.
Additionally, using multiple regions for failover protection and having a well-thought-out disaster recovery plan will give you peace of mind when it comes to the security of your data. Ask one of our Azure cloud engineers or Azure architects how to approach it best.





