How a Data Engineering Team Extension Can Help You Scale


Contents
Why clean, structured data — and the people behind it — make or break your AI ambitions.
In the rush to adopt AI, there’s one uncomfortable truth many companies overlook: if your data is a mess, no model can save you.
From Large Language Models to personalization engines, the success of AI systems depends on the quality of the data they’re trained on. But in reality, most organizations are still dealing with scattered, unstructured, or incomplete data.
That’s where data engineering comes in — and why it’s become one of the most critical (yet under-resourced) functions in the AI delivery chain.
The challenge is clear: experienced data engineers are in short supply. While hiring takes time and internal teams are often at capacity, project timelines continue to tighten.
To close that gap, more tech leaders are turning to data engineering team extension — embedding external specialists into their teams to accelerate delivery, improve data quality, and build scalable foundations for AI systems.
In this article, we’ll unpack what data engineering team extension actually means, when to use it, and how it helps you build the clean, structured, production-ready data pipelines your AI projects need to succeed.
What Is Data Engineering Team Extension?
Data engineering team extension is a collaboration model where external data engineers join your internal team—not as outside contractors, but as fully integrated contributors.
Unlike full product outsourcing, you stay in control. You manage your tools, data architecture, and priorities, while the extended team brings the extra expertise and bandwidth to move faster. From ingestion to transformation and validation, they help accelerate delivery without long hiring cycles or steep onboarding.
It’s a flexible, scalable approach. Whether you're consolidating data from multiple sources or productionizing pipelines for AI deployment, data engineering team extension gives you access to the right skills—exactly when you need them.
How It Differs From Other Models
- Team Extension: External data engineers embed into your workflows and tech stack. You manage the backlog; they boost delivery.
- Outsourcing: The provider takes full control of delivery. Useful for off-the-shelf pipelines, but harder to align with evolving internal goals.
- Managed Services: Delivery is handled externally under a service-level agreement. Efficient for repetitive tasks, but lacks day-to-day collaboration.
With data engineering team extension, the goal isn’t to hand off responsibility — it’s to strengthen your team with experts who work alongside you and help you move faster.
When to Choose Team Extension Over Hiring In-House
Building a strong in-house data engineering team can be powerful — but it’s also slow, costly, and difficult to scale on demand. Team extension offers a more agile path when timing, complexity, or talent gaps stand in your way.
You’re Under Pressure to Deliver AI – But Your Data Isn’t Ready
AI projects move fast, but clean, well-structured data doesn’t appear overnight. If your internal team is already stretched, team extension can help you tackle high-priority tasks like building ETL pipelines, cleaning data, and setting up storage — without slowing down delivery.
Your Needs Outpace Your Headcount
Data engineering needs are not static. One quarter, you may be focused on consolidating internal sources. Next, you’re cleaning third-party feeds, or prepping for real-time analytics. Hiring permanent staff for every edge case leads to overcapacity and inefficiency.
Team extension gives you a flexible way to scale expertise based on your current phase — without committing to full-time headcount.
Niche Skills Are Hard to Find (and Retain)
Finding experts in areas like stream processing, schema design, or compliance isn’t easy. Retaining them is even harder. With team extension, you can bring in engineers with niche experience in days — not months.
You Need to Speed Without Sacrificing Quality
Whether you're building a GenAI prototype or launching a new data product, speed matters. With embedded engineers who follow your workflows and standards, team extension helps you move quickly — while maintaining quality, security, and compliance.
What Data Engineers Actually Do
Data engineers are the architects and plumbers of any AI-driven system. Their job is to ensure that the data feeding into machine learning pipelines is clean, structured, and ready for use — not sitting fragmented across spreadsheets, SaaS tools, or ungoverned databases.
Their work spans several critical areas:
- EDA - Exploratory Data Analysis: involve analyzing and visualizing datasets to understand their structure, detect patterns, identify anomalies, and evaluate data quality before AI model development or integration begins.
- Data ingestion: Automating the flow of data from sources like APIs, databases, logs, and third-party platforms into a central system.
- Cleansing and transformation: Fixing missing values, duplicates, and inconsistencies. Standardizing formats and preparing data for analysis or model training.
- Feature engineering: Creating new variables from raw data that improve model performance — like converting login timestamps into “days since last visit” or calculating customer lifetime value.
- Validation and quality control: Setting up rules and checks to make sure data is accurate, complete, and consistent. This includes schema validation, anomaly detection, and monitoring for drift.
- Building storage infrastructure: Designing scalable data lakes or warehouses with clear lineage, performance in mind, and proper access controls.
- Governance and security: Enforcing responsible data practices — including encryption, access management, and compliance with privacy regulations like GDPR or HIPAA.
Without this foundation, AI teams often spend more time fixing data than building models — leading to delays, frustration, and subpar results. Data engineers make sure that doesn’t happen.
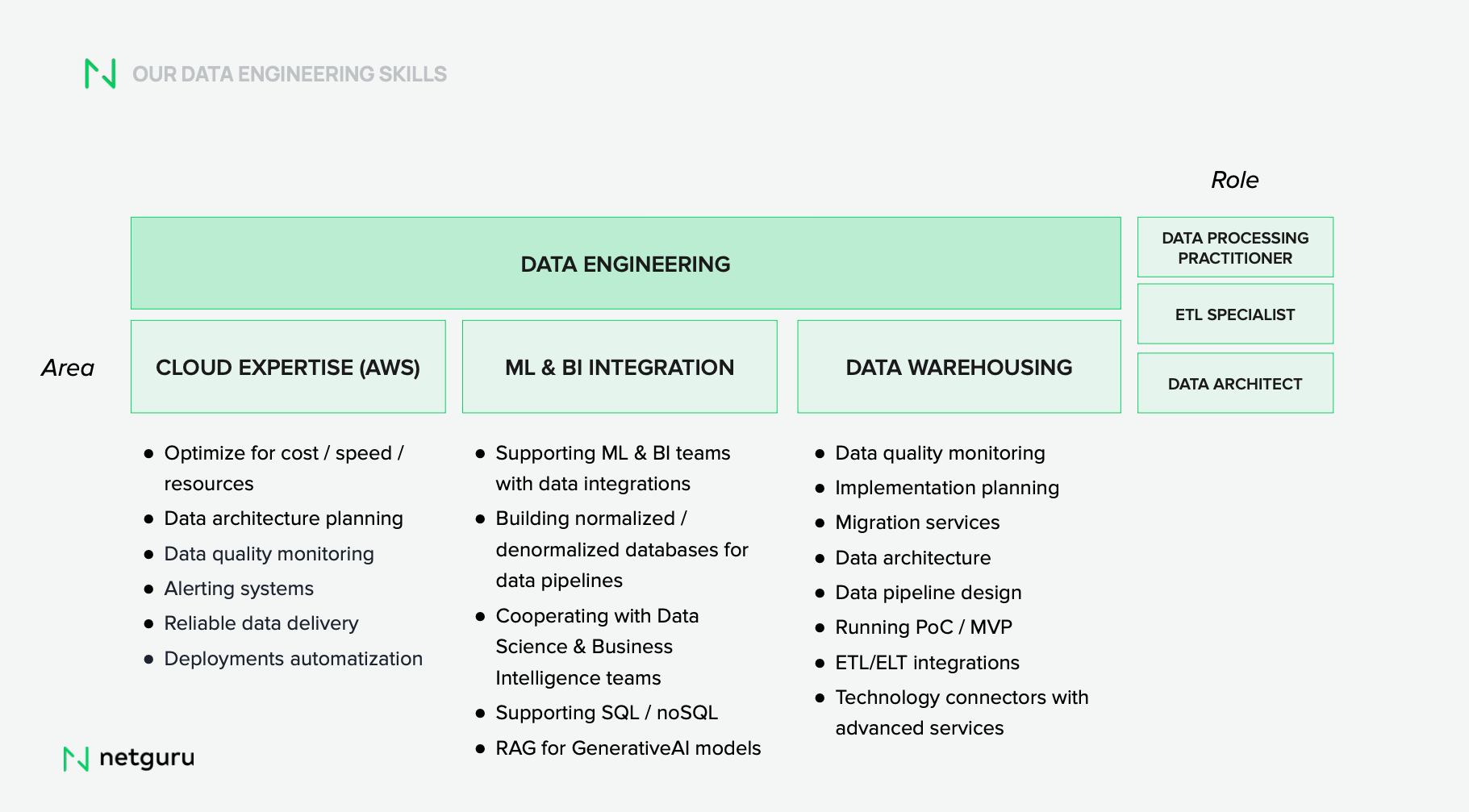
Netguru’s Data Engineering Specializations
Delivering high-quality data pipelines takes more than one type of expert. At Netguru, our data engineering team includes professionals with deep experience across core specializations — allowing us to match skills precisely to project needs.
Data Architect
Designs the overall blueprint for data management.
- Provides strategic guidance on how data should be collected, integrated, validated, and stored — then delivered to the right people, at the right time.
- Implements solutions based on DataOps practices with automated infrastructure and monitoring.
ETL Specialist
Moves and transforms data between systems.
- Supports migration from legacy databases to modern data warehouses, aligns formats, improves quality and consistency.
- Builds and maintains DAGs and scheduled workflows to ensure smooth data operations.
Warehouse Specialist
Optimizes storage and access in modern data platforms.
- Builds and manages daily warehouse operations efficiently — including the creation of data marts and orchestration of ELT flows.
- Prepares data for business intelligence tools and analytics teams.
Data Streaming Specialist
Enables real-time data processing.
- Builds resilient streaming analytics systems using cloud-native or serverless architecture, depending on scale and latency requirements.
- Processes high-velocity data streams (e.g., IoT, clickstreams) for live business insights.
What a Scalable Data Engineering Process Looks Like
A strong data engineering process isn’t a one-time fix — it’s a repeatable system that ensures your data is reliable, consistent, and ready for AI or analytics.
Phase 1 – Audit and Ingestion
Start by mapping out your data landscape. Data engineers profile sources — internal systems, third-party APIs, or cloud storage — to understand structure, volume, and quality. This helps uncover gaps like missing fields, inconsistent formats, or undocumented schemas.
Then, they set up ingestion pipelines (e.g., with Airbyte or custom scripts) to bring data into centralized storage like data lakes or warehouses.
Phase 2 – Transformation and Standardization
Raw data needs cleanup. Engineers remove duplicates, fix inconsistencies, standardize formats (like dates and currencies), and align labels across sources.
This is done using ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines — depending on your infrastructure. Engineers may also create new features (e.g., rolling averages or customer segments) to support modeling.
Phase 3 – Quality Assurance and Validation
Once pipelines are built, data is tested for completeness and accuracy. Engineers run checks for null values, schema mismatches, and outliers, flagging any issues before the data flows downstream.
For example, if user IDs must be unique and signup dates can’t be in the future, anomalies get caught early — not during model training.
Phase 4 – Ongoing Monitoring and Automation
Scalability depends on automation. Engineers use tools like Great Expectations, Deequ, or Talend to monitor data health continuously. These tools check for things like missing data, unexpected changes, or schema drift — and alert teams if something goes wrong.
This hands-off monitoring helps maintain trust in your data and ensures long-term success with AI.
By following this phased approach, you get reliable, well-documented pipelines that deliver clean, structured data — ready for analytics, machine learning, or real-time AI applications. It reduces rework, improves model performance, and sets a strong foundation for scaling your data strategy over time.
Real-World Impact: How Team Extension Helps
When internal capacity hits a wall, team extension can unlock major results — from better data quality to real-time AI workflows. Here’s how it’s worked for companies across fintech, energy, real estate, and ecommerce.
FairMoney
FairMoney is a fast-growing fintech company operating in multiple African markets. Faced with a surge of unstructured data and pressure to launch AI-powered features, they needed to stabilize their pipelines fast. By embedding external data engineers into their workflows, they gained the firepower to clean, organize, and activate critical data for production use.
Outcomes:
- Real-time fraud detection and KYC workflows
- Loan approval time reduced to 8 seconds
- Regional data ingestion streamlined across teams
NeedEnergy
NeedEnergy is a sustainability-focused startup helping optimize electricity usage and production across underserved regions. They needed a working prediction model and data platform to support fundraising and real-world validation. With help from extended data engineers and ML specialists, they launched an AI demo and secured Techstars acceleration.
Outcomes:
- AI-powered energy prediction demo delivered
- Funding secured and entry into Techstars Web3
- Scalable foundation for sustainability-driven insights
.jpeg?width=1078&height=745&name=CS%20NeedEnergy%20graphic%20for%20landing%20pages%20(1).jpeg)
Newzip
Newzip is a US-based proptech platform that connects mortgage lenders with real estate agents to simplify home buying. They wanted to test if hyper-personalized content could increase user engagement. With external support, they built a full AI PoC — from architecture to deployment — in under two months.
Outcomes:
- 60% increase in engagement
- 10% increase in conversions
- Fully operational PoC in just 6 weeks, serving 10k+ users
NEONAIL
NEONAIL, part of the global COSMO Group, needed a virtual try-on app for manicures that delivered a realistic and responsive user experience. By extending their team with ML and computer vision experts, they created a cross-platform AR app that drove digital sales and enhanced the online shopping journey.
Outcomes:
- Realistic AR-powered nail color preview
- iOS and Android support with seamless performance
- Boosted customer confidence in online purchases
 What to Look for in a Data Engineering Partner
What to Look for in a Data Engineering PartnerNot all support is created equal. A strong data engineering partner brings more than technical chops — they bring the right mindset and integration approach.
How to evaluate vendors - look for:
- Tooling and Infrastructure Experience: Familiarity with modern ETL tools, data validation platforms (e.g., Great Expectations, Deequ), and cloud-native data lakes.
- Governance and Compliance Know-How: Ability to design secure, auditable pipelines that comply with privacy and regulatory standards.
- Process and Cultural Fit: Teams that integrate smoothly into your workflows — Agile, DevOps, or custom setups — and communicate proactively.
- AI-Readiness Understanding: Engineers who know what it takes to support downstream ML and GenAI use cases, not just raw data delivery.
The right partner doesn’t just “build pipelines.” They build for your business goals — with future AI use in mind.
Conclusion – Solid Data, Smarter Models
Every AI initiative stands on one foundational truth: garbage in, garbage out. Without clean, structured, and accessible data, even the best models fail to deliver real value.
That’s why scalable data engineering — and the ability to extend your team at the right moment — is critical. It’s how you move from fragmented datasets to AI-ready infrastructure.
If you want AI that works in the real world, start with your data — and make sure you have the right team behind it. Team extension offers the flexibility, speed, and expertise to help you get there faster.





