🤖MLguru #1: Noise-free Images, Video-to-video Translation, GraphPipe Open-sourced by Oracle, and Machine Learning Cheatsheets
-450071-edited.jpg?width=50&height=50&name=Opala%20Mateusz%202%20(1)-450071-edited.jpg)

The newsletter for everyone interested in AI, ML, and related technologies. Every second week, we’ll be sharing top industry news you shouldn’t miss and explaining what lies behind complex AI/ML algorithms.
NVIDIA’s Algorithms Remove Watermarks and Noise from Photos
We all have heard about many impressive applications of Deep Learning already, so just removing watermarks might not be especially mind-blowing. So the first important thing about this work is that the paper is called Noise2Noise! You might have guessed that already: the neural networks learn only from corrupted images!
You can find in the paper:
Without ever being shown what a noise-free image looks like, this AI can remove artifacts, noise, grain, and automatically enhance your photos.
The whole trick actually seems trivial from the statistical point of view! Authors of the paper benefit from the fact that the L2 loss estimate remains unchanged if targets are replaced with random numbers whose expectations match the targets. It means that:
… we can, in principle, corrupt the training targets of a neural network with zero-mean noise without changing what the network learns
They’ve got some encouraging results:

NVIDIA’s video-to-video translation
There are more amazing updates from the researchers at NVIDIA: video-to-video translation, for instance! We’ve already seen a lot of impressive work on image-to-image translation, but additional dimensions bring additional difficulties such as the coherence of generation across time. You can check it here: https://github.com/NVIDIA/vid2vid
How does it work?
Surprise, surprise… It’s a Generative Adversarial Network!
The creators designed a sequential generator that models the conditional probability of a real image given the source image (so, for example, a face image given an edge image). They make a Markov assumption, so the generation of the frame depends only on:
- the current source image
- past L source images
- past L generated images
A small L (i.e. equal to 1) can cause the training to be less stable. However, large L values require lots of GPU memory and increase training time. The creators opted for L=2, which works fairly well.
The algorithm’s creators introduce two discriminator networks:
- a conditional image discriminator that ensures that each output frame resembles a real image given the source image,
- a conditional video discriminator that ensures that consecutive output frames resemble the temporal dynamics from a real video.
Experiment details
- 40 epochs with Adam optimizer
- 8 V100 GPUs with 16Gb of memory
- 4 GPUs for generator training, 4 GPUs for discriminators
- Training takes 10 days
Learn more
GraphPipe Open-sourced by Oracle
The deployment of Machine Learning models is a very interesting topic, and no established gold standard way of doing it exists. JSON serialisation tends to be too slow for data that is fed into or produced by ML models. Personally, I’m a huge fan of the MSGPACK serialisation, because it’s crazy fast and makes it easy to serialise multi-dimensional numpy arrays. I’ve used dill for remote function calls in Python, which works great, and you can achieve autocompletion in PyCharm for remote objects! However, all of it is very custom, so it’s always good to hear about new packages that try to make deployment simple.
So what is GraphPipe?
GraphPipe is a protocol and collection of software designed to simplify machine learning model deployment and decouple it from framework-specific model implementations.
Why it matters
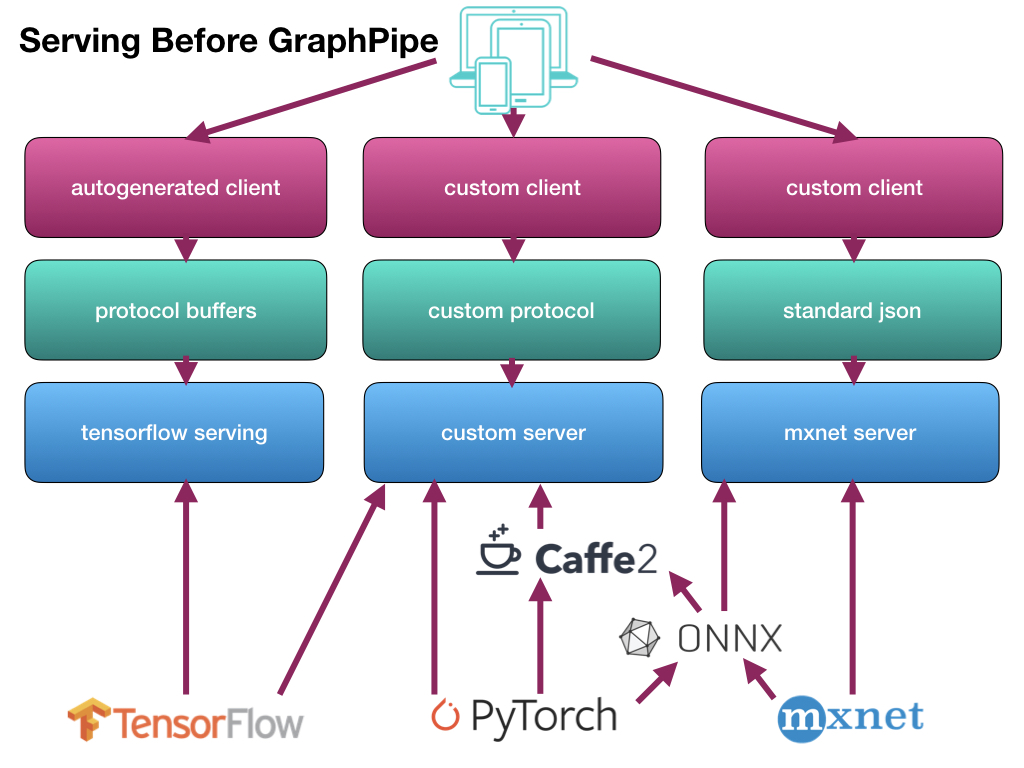
- Model serving network protocols are tied to underlying model implementations
- PyTorch and Caffe2 do not provide an efficient model server in their codebase
- ONNX exists, but tackles the vendor-coupling problem by standardising model formats rather than protocol formats. This is useful but challenging, as not all backend model formats have fully equivalent operations. This means a simple conversion doesn't always work, and sometimes a model rewrite is necessary
- It’s important to have one shared protocol for communicating with Machine Learning models
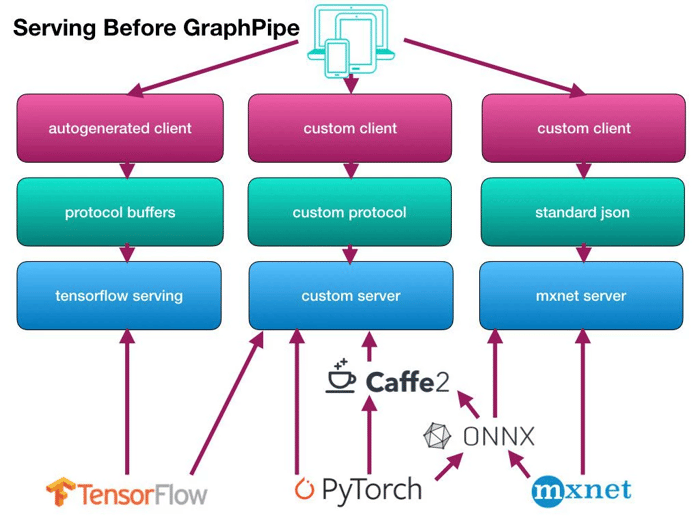
Source: https://oracle.github.io/graphpipe/guide/user-guide/_media/gparch.001.jpg
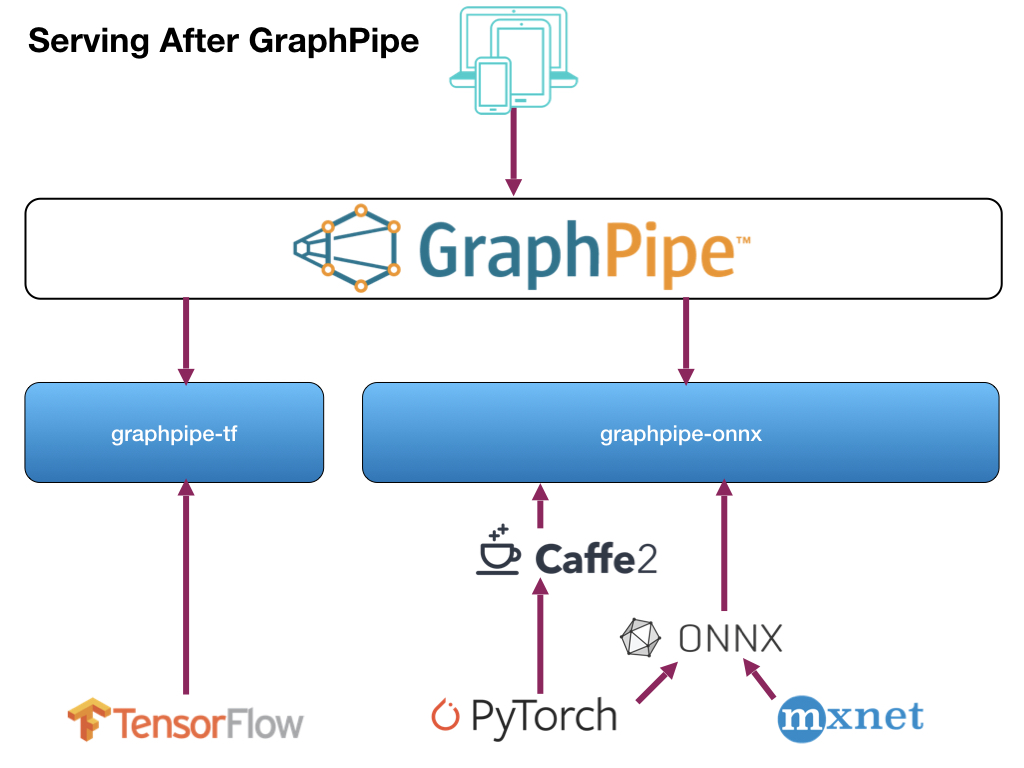
GraphPipe provides:
- ML transport specification based on FlatBuffers
- Support for TensorFlow, Caffe2, PyTorch, ONNX, and MXNet
- Efficient client implementations in Python, Java, and Go
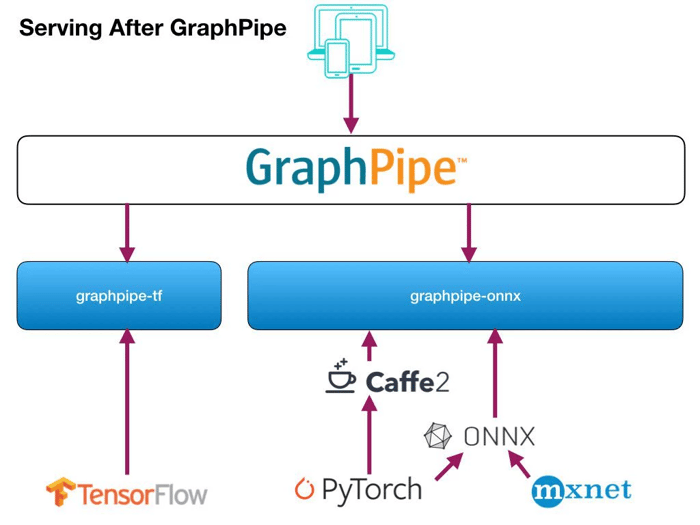
Source: https://oracle.github.io/graphpipe/guide/user-guide/_media/gparch.002.jpg
I have to say that weren’t lying about its simplicity:
from graphpipe import remote
import numpy as np
request = np.array([[0.0, 1.0], [2.0, 3.0]])
result = remote.execute("http://127.0.0.1:9000", request)
print(result)Machine Learning cheatsheets
Stanford has released a few nice machine learning cheatsheets. You can check them out below:Machine Learning cheatsheets
That’s all exciting news for today. We’ll be back in two weeks with more inspiration, hot updates, and tips from the ML world. Let us know what you would like to read more about!
-450071-edited.jpg?width=240&height=240&name=Opala%20Mateusz%202%20(1)-450071-edited.jpg)













{kind=link}
{kind=link}
{kind=link}
{kind=link}