IDP Solutions - Custom Development vs Ready-To-Use Software


It’s a challenge that casts a shadow on business operations efficiency in a number of companies.
This article is a comprehensive guide to the range of intelligent document processing (IDP) solutions and how and when you can use them in your business.
The increasing digital acceleration of all forms of business has led to a huge spike in the amount of data that companies have to process. This, in turn, has given rise to an important new business function dedicated to data handling and processing, making traditional, manual document processing too time consuming for many.
Indeed, the International Data Corporation estimates that by 2025 worldwide data will have exceeded 175 zettabytes. To give you an idea of exactly how much that is: one zettabyte is a trillion gigabytes, and if you were to store that 175 zettabytes on blu-ray discs, you’d have a pile of discs that could reach the moon — 23 times! Manual document processing at this scale is simply not possible and, even if it was, would be prone to human error. So, how can businesses overcome this obstacle?
There are different kinds of data. Some is structured — that is, data that is stored within readable formats, such as tables with rows and columns from which data extraction can be programmed. Some of it is unstructured — and this can include image documents or wholly text-based data.
Right now, 80% of all the data available is believed to be in unstructured documents. Considering the need to process large volumes of data like this, it is clear that finding a way to automate current document processing methods and convert paper-based documents to digital is becoming absolutely essential. IDP solutions are one way to do that.
What is intelligent document processing (IDP)?
Intelligent document processing is a set of techniques used to extract data from the document using machine learning and artificial intelligence. It is often assisted by OCR - a technique for automating data extraction from printed or written text (like scanned documents or image files) and converting the text into a machine-readable form to be used for data processing like editing or searching.
IDP solutions can process any kind of document, whether it is digitally typed or handwritten, or scanned. IDP is underpinned by machine learning, and its main ML subfield is natural language processing (NLP).
However, since documents often contain pictures as well as text, computer vision algorithms can be used as well. In most cases the IDP process is consistent, with a number of standard steps, but specific cases may require less or more work/stages.
Standard IDP steps are:
- Pre-processing to improve the document’s quality by applying techniques such as noise reduction, deskewing, etc. Typically documents have varying quality levels, and this can have a huge impact on the whole IDP process, therefore it is crucial to apply this step.
- Classification to decide which parts of the document should go to particular workflows. Enterprise documents contain various types of information and are usually multi-page. Workflows differ for each data type, so it is very important to determine where a particular document piece should go.
- Extraction to extract insights from the documents. Trained machine learning models extract data like names, fees, and dates from pre-processed and classified documents.
- Post-processing to put extracted data through a validation flow. The purpose of this step is to eliminate minor mistakes from extracted data like common typos or misspellings. It’s also possible to involve human-in-the-loop validation here.
What types of data do IDP solutions work with?
There are a number of documents used by businesses of all kinds, like invoices, online forms, legal documents, reports, and so on. The document structure is a very important factor in identifying the correct IDP solution, and different types of documents may require a unique IDP approach.
There are three main document types in terms of data structure:
- Structured data includes fixed-format documents, like questionnaires and application forms. The layout for these documents often includes other graphical elements like boxes, separators, and checkmarks. However, their position is fixed. Usually, simple extraction based on field positions and fixed relations between them is sufficient.

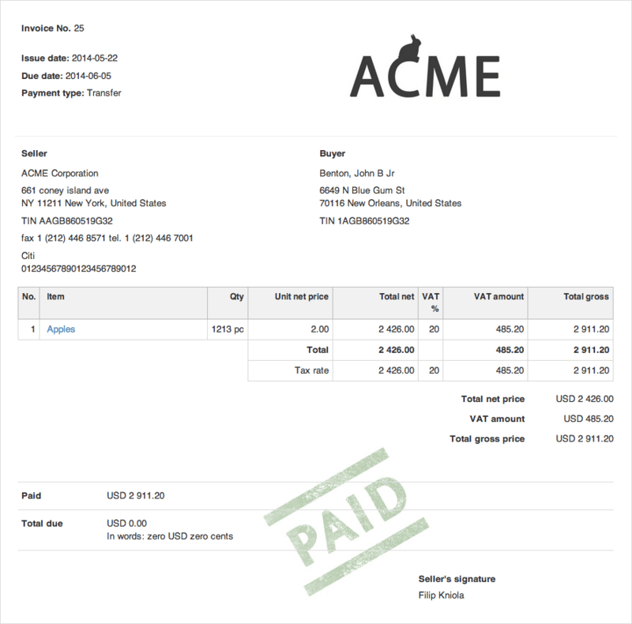
- Semi-structured data includes multi-variant documents with flexible layouts. Similar to structured documents, there is some visual layout to organize text as well. However, this format is more flexible, there are often many different variants with specific layouts (e.g., different invoice layouts coming from different vendors). This requires an IDP solution capable of quickly learning new formats and the positions of fields.
- Unstructured data includes documents with plain, natural language text. There is little or no visual organization of text. To extract any information, whole blocks of text need to be read and understood first. This is the most complex case and requires segmentation, entity extraction, and large volumes of data samples to learn.

On top of that, another criterion to take into account is the source of a document and the file format used to store it. An image created as a photo or with a scanner is quite likely not to be clear or to have various kinds of distortions like skew, noise, changed orientation, and overlap with other elements.
This is called an image document. They are usually hard to process and require several techniques to even start with processing, including computer vision, image processing, and extracting text from images.
Digitally-born documents are on the other side of the document typology. They are created directly on a computer, server, or website, usually in a fully automatic way. This type of document is much easier to process and extract information from.
When it is better to build a custom IDP solution
Ready-to-use IDP solutions can help with processing physical documents in many cases — but there are some business processes where extra customization might turn out to be a huge asset for the seamlessness of your business activities.
If your documents are entirely unstructured, or contain multiple different structure types within the same document, a custom IDP solution may prove to be more efficient for your project, making sure that the variety of usable data you’re processing is accounted for, and accuracy is maintained.
Let’s take a look at when dedicated IDP solutions are the right choice:
Most of your documents are unstructured
As mentioned before, some documents contain only unstructured, plain text, without any tables or fields, which can be problematic to process with ready-to-use software. Solutions that allow customization can handle that issue and process them effectively. They are more flexible and thus offer a wider range of processing capabilities.
This is particularly useful in organizations that process many different kinds of documents from old and new sources. In the legal or finance sector, for instance, companies need to process complex legal documents, handwritten accounts, and statements in large numbers.
In this case, you would need a custom development IDP solution to limit the processing workload and eliminate manual work of document processing.
Multiple structure schemas of documents
When your documents come from all types of sources and are either semi-structured or their structures differ from one another. In case of multiple structure schemas, a dedicated IDP solution allows you to account for all the variations and will process each type according to its unique schema.
A primary example of this is having invoices coming in from different vendors. The information may be mostly the same in these documents, but their structure will be different, the fields arranged in different ways.
Profit and loss reports can also look totally different, depending on a company’s profile and industry, and the same goes for financial balance sheets. It’s vital that these documents are processed accurately. Again, building a custom IDP application to process the same data types from different sources is the better option here, as it enables more time-efficient and accurate data processing.
Answering individual business needs in document processing
Every business has unique needs and resources, and while out-of-the-box IDP solutions can work for basic cases, customized solutions are ideal when those unique needs arise.
Most ready-to-use IDP applications offer some built-in functionalities, such as fees extraction, but these features do not cover every scenario or eventuality, or even more complex needs. After all, business is complicated and sometimes unpredictable, so there are often situations where extra features are required for the process to go smoothly.
The legal sector is a great example here with the use of legal documents analysis to detect abusive clauses, or the ability to generate closed and open questions from a specific document.

Example of IDP open and closed question generation
Training machine learning models for better performance
Improved accuracy and fast computation are another two cases when you should consider training a machine learning model in a custom-built IDP solution. However, it requires large volumes of data or documentation to train the ML model, which often poses a challenge to businesses to deliver.
There are a variety of NLP tasks that can be solved with machine learning, including document classification, summarization, named entity recognition, and more. This can massively help any business by improving the reliability and speed of document processing, as well as establishing an ongoing and continuous method for enhancing the quality of results, contributing to long-term success.
Ready-to-use IDP solutions
While all of the above are great reasons to use custom IDP solutions, there is a lot of ready-to-use intelligent document processing software on the market right now. Most of it is designed to extract data to help solve specific business problems, such as invoice processing or finding abusive clauses in legal documents.
This might turn out to be a crucial asset just to even start automated document processing at all. Processing an invoice incorrectly, for example, can lead to lost revenue and potentially even legal problems, so the availability of ready-to-use document processing solutions is a big help to businesses.
These products use techniques mentioned above, such as natural language processing and machine learning, but also utilize rules-based algorithms and robotic process/intelligent automation to ensure standardization of performance in document processing.
Each available product is designed to process a specific document type and, to add to this, they are usually designed to process fully structured or semi-structured documents. As such, the set of services is usually limited. If a more customizable and unconventional functionality is required, a ready-to-use IDP application might fail to meet your actual business needs.
Some of the companies offering ready-to-use IDP applications include:
- ABBYY FlexiCapture: document classification (fully automated recognition of each document’s type), recognition of handwritten data.
- Nanonets: automated processing of invoices, driver licenses, passports and ID cards.
- Klippa: processing of medical, legal, HR documents etc., document classification, handwritten data recognition.
- Hypatos: classification of documents in e-mail attachments, relevant data extraction.
There’s also an obvious benefit of using off-the-shelf IDP software — in most cases it’s cheaper to automate tasks with pre-set rules than to custom develop.
It also tends to take less time to implement a ready-to-use solution, as it requires less technical expertise and can bring the benefit of intelligent document processing to organizations without the necessary resources to develop customized tools. So if you need a quick fix for structured document processing, they are probably a more affordable option to start with.
Which IDP solution should you use?
The digital acceleration of business has driven the need for more effective data processes, and this must be achieved through the use of technology, specifically artificial intelligence and automation.
AI technologies have delivered intelligent document processing, which has huge potential to help almost any kind of business to save money and time and gain accuracy in document output. Companies, depending on their needs, can choose between two approaches: a custom IDP solution or ready-to-go software, each underpinned by intelligent automation.
The challenges mentioned above will influence your decision, so it’s useful to conduct a review of your needs and capabilities before deciding which services will support your business best.
If you mainly process structured documents with simple content and want to complete some casual, routine tasks, ready-to-use intelligent document processing solutions would be the best option. It would also save on the time required to build and train a custom model.
However, if you have a lot of documents containing only plain text or even invoices coming from a lot of different vendors, or you want some extra tasks to be performed, it might be better to build a custom solution that is designed to meet your specific needs.
If you want to learn more about the IDP solutions tailored to your business needs, or have a project you want to discuss, get in touch with the experts at Netguru today.













