Chatbot KPIs that prove ROI to leadership (with benchmarks)


Contents
The exact chatbot KPIs to track for ROI: containment rate, CSAT, FCR, cost per conversation, and more. Benchmarks and a working ROI formula included.
The 5 chatbot KPIs that actually prove ROI
Track these five KPIs first: containment rate, cost per conversation, first contact resolution (FCR), CSAT, and escalation rate. Together, they tell you whether your chatbot is handling volume, reducing cost, resolving issues, satisfying users, and failing gracefully, in that order of diagnostic priority.
|
KPI |
Why it matters |
|---|---|
|
Containment rate |
Are conversations resolved without a human? This is your primary throughput signal. |
|
Cost per conversation |
Divide total chatbot operating cost by conversation volume, your ROI denominator. |
|
First contact resolution (FCR) |
Containment without resolution is just deflection. FCR confirms quality, not just volume. |
|
CSAT |
Lagging indicator of user experience; drop below 3.5/5 and containment gains erode trust. |
|
Escalation rate |
High escalation signals intent recognition gaps before CSAT has time to show the damage. |
Quick win: pull your current containment rate and FCR side-by-side today. A gap wider than 20 percentage points means your bot is handling volume but not solving problems.
Why most chatbot dashboards mislead leadership
The default chatbot dashboard shows containment rate, session volume, and response time. All three can look healthy while your chatbot is quietly destroying customer trust.
Containment rate and deflection rate sound interchangeable, they are not. Containment rate measures the percentage of conversations the chatbot handles without human intervention. Deflection rate measures the percentage of conversations that never reach the support queue at all. A bot can contain a conversation by exhausting the user until they give up. That inflates containment without any actual resolution. We audited a chatbot deployment at a 200-person SaaS company and found a containment rate of 61% paired with an FCR of 38% , the bot was handling volume, but fewer than four in ten users left with their problem solved.
The metric underneath both numbers is intent recognition accuracy: the percentage of user inputs the NLP model correctly classifies. When accuracy drops below roughly 80%, fallback rate spikes, the bot triggers its default 'I didn't understand' response more often, which users experience as a broken product rather than a routing failure. Most dashboards don't surface intent recognition accuracy at all; it lives in NLP logs that leadership never sees.
Vanity metrics get reported upward because they're easy to extract. The diagnostic layer, intent accuracy, fallback rate by intent cluster, FCR segmented by conversation path, requires deliberate instrumentation from the start. Without it, you're optimizing for numbers that don't correlate with outcomes.
Customer-facing chatbot KPIs: What to track and why
The metrics below sit on the customer side of the ledger, they tell you whether your chatbot is actually resolving problems, not just absorbing traffic. Each one is worth tracking independently, because they fail in different directions, and they reinforce the broader benefits of AI chatbots in modern customer service.

Containment rate: The volume signal
Containment rate measures the percentage of sessions the chatbot closes without handing off to a human agent. A high containment rate means your bot is handling volume. It says nothing about whether customers got what they came for.
Industry benchmarks put healthy containment rates between 70–85% for transactional use cases (account lookups, order status, password resets) and 50–65% for conversational support global conversational AI market estimated at $11.58bn in 2024, projected to reach $41.39bn by 2030 (Grand View Research, 2024). If your rate falls below 50%, the bot's intent recognition is likely the bottleneck, not conversation design, and you may be drifting toward the common patterns behind why many chatbot implementations fail. Check your NLP confidence threshold: if your fallback trigger is set too low (say, below 0.6), low-confidence intents route to humans before the bot has a real chance to resolve them.
We audited a chatbot deployment at a 200-person SaaS company and found containment rate was 61% but first contact resolution was 38%. The bot was handling volume but consistently closing sessions before confirming resolution, a design flaw that containment rate alone would never surface.
CSAT and NPS: The trust indicators
CSAT and NPS measure whether customers leave the interaction satisfied and whether they'd recommend your product off the back of a support experience. Both are lagging indicators, by the time they drop, the damage is done.
For chatbot-specific CSAT, benchmark targets vary by industry, but Seventh Edition State of Service Report surveyed 6,500 service professionals worldwide (Salesforce, 2024) puts average digital channel CSAT at around 75–80%. Chatbot CSAT typically runs 10–15 points lower than live agent CSAT, an acceptable gap if the chatbot is handling Tier-1 volume, a red flag if it's handling anything requiring nuanced judgment.
Track NPS segmented by resolution path (bot-only vs. bot-then-agent). If bot-escalated sessions produce dramatically lower NPS than fully contained ones, your escalation handoff is broken, either the context isn't transferring or wait times spike post-escalation.
FCR and escalation rate: The resolution pair
First contact resolution (FCR) and escalation rate are two sides of the same question: did the customer get a complete answer without needing to come back or go elsewhere?
For example, ARC Europe implemented a custom AI chatbot to support post-incident service requests through WhatsApp. Delivered by Netguru, the solution asks drivers only a few targeted questions to identify whether they need a taxi, hotel, or replacement vehicle, then guides them to the right next step. In a case like this, the most important KPIs are not just conversation volume, but whether the customer completes the flow, gets routed to the right service, and avoids unnecessary escalation.
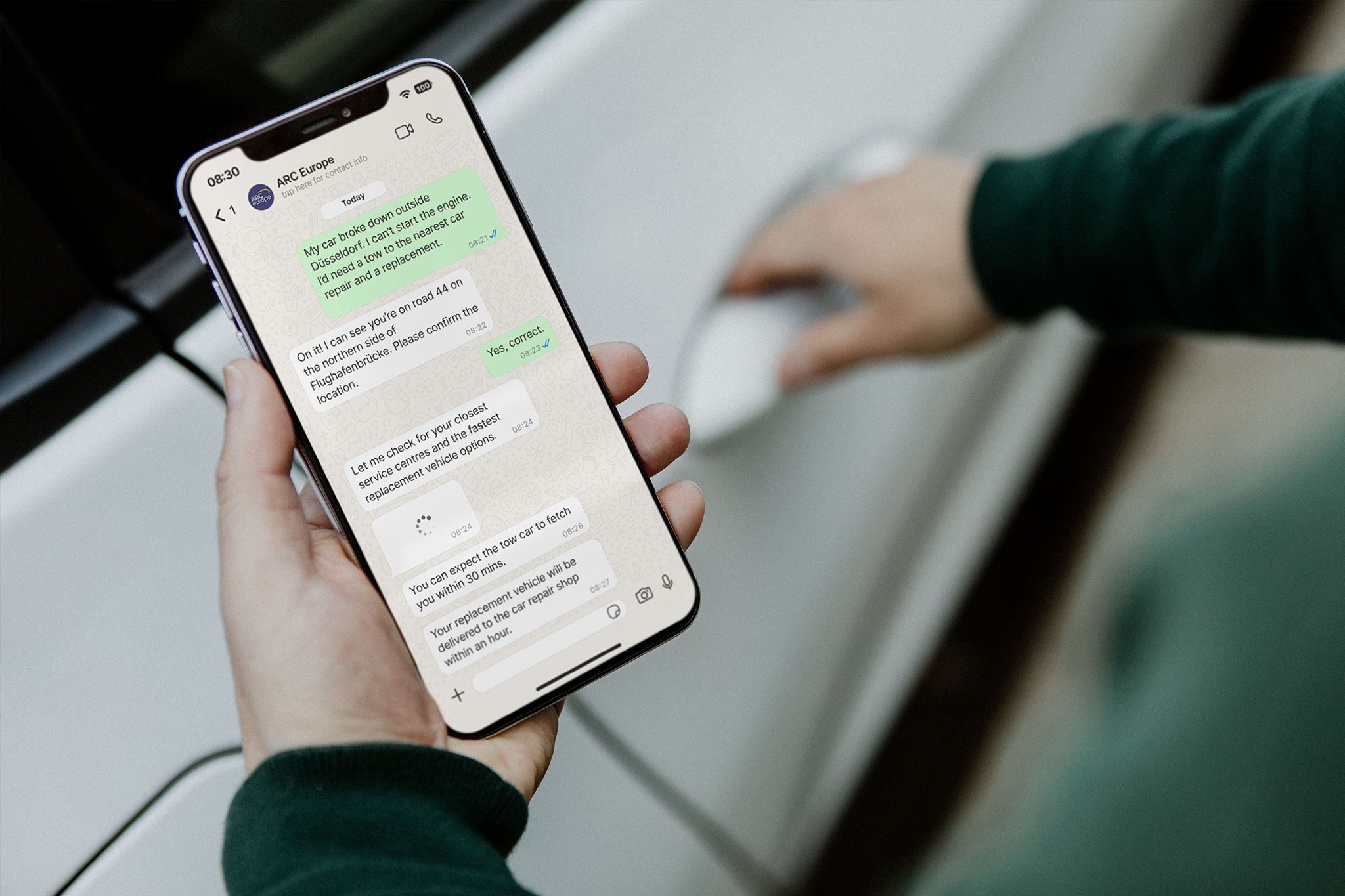
⚑ A chatbot FCR below 40% in a high-volume support context signals that the bot is handling surface-level queries while deflecting anything substantive to agents, or to a second contact entirely. The industry average FCR for live agents sits around 70–75%; expect chatbot FCR to run lower, but track the gap over time rather than the absolute number.
Escalation rate should be read alongside escalation reason. Most platforms (including Chatguru) log escalation triggers, "user requested agent," "low confidence," "sentiment threshold exceeded." If 60% of escalations come from low-confidence intent matches, the fix is model retraining, not conversation redesign; if users drop out despite accurate intents, you likely have a chatbot UX and conversation design problem instead.
|
KPI |
Healthy Range |
Warning Sign |
|---|---|---|
|
Containment rate |
65–85% |
Below 50% |
|
CSAT (chatbot) |
70–80% |
10+ pts below agent CSAT |
|
FCR |
40–60% |
Below 35% |
|
Escalation rate |
15–30% |
Above 40% or rising month-over-month |
Session completion rate deserves a separate watch: it measures the percentage of sessions where the user reached a defined endpoint (resolution, escalation, or explicit exit) rather than simply abandoning mid-flow. Drop-off before completion usually points to a specific intent or dialog path where the bot loses the thread, fixable once you know where it is.
What containment rate benchmark should you target?
For tier-1 support: password resets, order status, FAQ-level queries , a containment rate between 65% and 85% is the realistic target range. Below 65%, the chatbot is handling volume but leaning too heavily on human fallback. Above 85%, scrutinize your CSAT and FCR before celebrating: high containment with poor resolution quality means you're containing frustration, not solving it.
Containment rate and deflection rate are not the same metric. Containment means the session closed fully within the bot, no escalation, no callback request. Deflection means the conversation was routed away from a live agent regardless of whether the issue was resolved. A session where the user abandoned after three failed bot turns counts as deflected, not contained.
Intent recognition accuracy is the diagnostic layer underneath both numbers. If your containment rate drops, check NLP confidence scores first, a spike in low-confidence intents usually precedes a fallback cascade before it shows up in containment data.
What csat and NPS scores should a chatbot hit?
A CSAT score of 75–85% is the achievable baseline for a well-tuned customer-facing chatbot, below 75% signals resolution gaps, not just UX friction. Human-assisted interactions typically score 85–90% Seventh Edition State of Service Report surveyed 6,500 service professionals worldwide (Salesforce, 2024), so the gap narrows as intent recognition improves.
NPS interpretation is different for a chatbot than for a brand. Bot-specific NPS measures channel satisfaction, not product loyalty, a score above 20 is solid; above 40 means the experience is actively reinforcing brand perception.
Session completion rate is the leading indicator to watch alongside CSAT. In our experience, completion rates below 70% predict CSAT scores under 75% almost without exception, users who abandon mid-session rarely return satisfied. Fix completion first; CSAT follows.
Internal efficiency KPIs: Cost, aht, and agent utilization
Cost per conversation is where chatbot ROI becomes undeniable to a CFO. A human agent interaction costs $6–12 on average; a bot-handled conversation typically runs $0.10–0.50, depending on infrastructure and NLP provider costs. At 10,000 conversations per month, that difference compounds fast, even at a conservative $6 human baseline versus $0.30 bot cost, you're looking at $57,000 in monthly savings before accounting for quality adjustments.
That number only holds if the bot is actually resolving queries. Cross-reference cost per conversation with your containment rate and FCR to avoid the trap of cheap-but-useless deflection, we've seen deployments where cost per conversation looked excellent on paper until FCR revealed the bot was generating repeat contacts at twice the normal rate.
AHT and agent utilization move together. When a chatbot handles tier-1 triage, collecting account details, categorizing intent, surfacing relevant documentation , agents receive escalations pre-loaded with context. That reduces AHT on escalated tickets by 15–25% in our experience, even though the agent never touched the initial interaction. Zendesk benchmark data suggests that context-rich escalations cut average handle time by roughly 20% compared to cold transfers 83% of consumers believe experiences should be better than they are today (Zendesk CX Trends Report 2026, 2026).
Agent utilization rate tells you whether that AHT reduction is translating into capacity. If AHT drops but utilization stays flat, agents are absorbing more volume, which is the right outcome. If utilization drops without a corresponding headcount reduction or CSAT improvement, the efficiency gain is leaking somewhere.
Time to first response is the metric customers feel most acutely. A bot responding in under two seconds versus a human queue averaging four to eight minutes sets the tone for the entire interaction. Track it separately for bot-only, bot-to-human, and human-only journeys to isolate where delays accumulate, and read it alongside broader AI agent success and ROI metrics.
Escalation rate acts as a pressure valve reading. A rate above 40% suggests the bot's intent recognition isn't covering enough of the real traffic distribution, not a UX problem, a training data problem. Tools like Chatguru surface escalation triggers by intent cluster, which makes it faster to identify which topics need additional training rather than guessing from aggregate numbers.
How to calculate chatbot ROI: A working formula
The core formula is straightforward:
ROI = (deflected conversations × cost per human interaction) − total chatbot cost
To make this work in a board deck, you need clean inputs. Here's a concrete example:
|
Input |
Value |
|---|---|
|
Monthly conversation volume |
10,000 |
|
Containment rate |
65% |
|
Deflected conversations |
6,500 |
|
Cost per human interaction |
$8.00 |
|
Gross savings |
$52,000 |
|
Chatbot monthly cost (infra + licensing) |
$4,500 |
|
Net monthly ROI |
$47,500 |
Two inputs that executives consistently miscalculate:
Escalations erode deflection savings. If 20% of "contained" conversations still require agent follow-up (a common pattern when containment rate and FCR diverge), your real deflected volume is closer to 5,200, not 6,500. Model escalation rate explicitly, otherwise you're presenting a best-case number that ops will disprove in quarter one.
AHT changes when agents handle harder cases. As a chatbot absorbs routine queries, average handle time on escalated conversations rises. Factor this into agent utilization rate projections, or headcount savings will look smaller than forecast.
For a deeper read on whether the underlying business case holds, see are chatbots worth it.
Leading vs. lagging indicators: Diagnose problems early
Most chatbot programs catch problems in CSAT scores, weeks after the damage is done. Leading indicators give you diagnostic signal while you can still act.
Leading indicators reflect what's happening inside the conversation mechanics right now:
- Intent recognition accuracy: the share of user inputs correctly classified by your NLP model. When this drops below ~85%, you're generating noise throughout every downstream metric.
- Fallback rate: directly tied to NLP confidence thresholds. If your model routes to a fallback response whenever confidence falls below a set threshold (say, 0.7), a rising fallback rate tells you the model is encountering out-of-vocabulary intents or distribution shift, before users start complaining.
- Session completion rate: the proportion of sessions that reach a defined end-state rather than dropping off mid-flow. A declining rate points to broken conversation paths or unresolved intent gaps.
Lagging indicators confirm business impact after the fact:
- FCR and CSAT measure resolution quality and satisfaction, meaningful, but slow to surface.
- Escalation rate tracks how often the chatbot hands off to a human agent. A rising escalation rate confirms what your leading metrics already told you.
In our experience, teams that monitor intent accuracy and fallback rate weekly catch containment problems two to three sprints earlier than teams watching CSAT alone, mirroring the lessons from AI failure examples that shaped reliable AI agents.

Employee-facing chatbot KPIs: IT helpdesk and hr self-service
Internal chatbots operate under different performance expectations than customer-facing ones, and they're measured differently as a result, especially when they're embedded into a broader AI-powered transactional ecosystem.
For IT helpdesk deployments, the primary KPIs are FCR and containment rate. A password reset or VPN access request that the bot resolves without a ticket being opened is a full success. IT helpdesks typically see containment rates of 70–90% for structured, repeatable queries, significantly higher than customer service deployments because the intent space is narrower and the workflows are deterministic.
For HR self-service (PTO requests, benefits lookups, onboarding checklists), the equivalent metric is self-service completion rate: the percentage of sessions where the employee completed their task without escalating to an HR generalist.
AHT matters here too, but the baseline shifts. In our experience auditing internal deployments, the meaningful comparison isn't bot AHT vs. human AHT, it's bot AHT vs. ticket queue wait time, which often runs 4–24 hours.
Agent utilization rate closes the loop: if your IT team's utilization drops after bot deployment, that's headcount capacity recovered, not idleness. Track it quarterly against ticket volume to surface the productivity gain.
How Chatguru maps KPI data to ROI reporting
Chatguru's reporting layer is built around the metrics that finance and operations teams actually need to see, not raw conversation logs. Out of the box, it surfaces containment rate, CSAT, cost per conversation, and escalation rate in a single dashboard, mapped directly to estimated cost savings.
For teams running Dialogflow-powered chatbots, Chatguru pulls intent recognition data alongside surface KPIs, so a drop in CSAT can be traced back to a specific intent cluster rather than treated as a general quality problem. Zendesk and Intercom integrations feed ticket and AHT data into the same view, which means you can calculate cost-per-conversation against a live human-agent baseline without building a separate data pipeline.
In our experience, this is where most measurement frameworks break down: the KPI data exists, but it lives in three different tools. Having containment rate, CSAT, and escalation rate in one place is what makes ROI reporting credible to a CFO, not just legible to an engineering team.
Frequently asked questions about chatbot KPIs
What is a good containment rate for a customer service chatbot?
A well-tuned customer service chatbot typically achieves a containment rate between 70% and 85% after six months of training on production data. Anything below 60% usually signals intent coverage gaps or NLP model underfitting. Containment rate alone is insufficient, pair it with FCR to confirm that contained conversations are actually resolved, not just abandoned.
How do you calculate chatbot ROI?
The core formula is: (deflected contacts × cost per human-handled conversation) minus (chatbot operating cost) divided by chatbot operating cost. Cost per conversation for a human agent typically runs $5–$12 in B2C support; chatbot-handled conversations run $0.10–$0.50. The gap is where ROI lives, deflection volume is the multiplier.
What csat score should a chatbot target?
A chatbot CSAT of 70–80% is a realistic target for transactional use cases; complex advisory flows typically land lower. Seventh Edition State of Service Report surveyed 6,500 service professionals worldwide (Salesforce, 2024) If bot CSAT trails human-agent CSAT by more than 15 points, the escalation routing logic, not the NLP , is usually the problem.
Which chatbot KPIs matter most for an it helpdesk deployment?
For internal IT helpdesk bots, prioritize FCR, AHT reduction, and escalation rate over CSAT. Employee-facing bots are judged on speed and accuracy, not conversational warmth. Cost per conversation matters too: compare it against the fully loaded cost of a helpdesk ticket, which typically includes analyst time and ticketing overhead.
What is the difference between containment rate and deflection rate?
Containment rate measures the percentage of conversations the bot handles without transferring to a human agent, regardless of whether the user's issue was resolved. Deflection rate measures conversations that would have reached a human channel but were handled by the bot instead, usually benchmarked against a pre-bot contact volume baseline. Containment is an operational metric; deflection is a cost metric. Tracking both is necessary because a bot can contain conversations through user drop-off without deflecting genuine demand.
Next step: Build your chatbot KPI dashboard
If your chatbot is handling volume but your FCR and cost per conversation data live in separate spreadsheets, you're measuring activity, not ROI. A unified KPI dashboard pulls containment rate, CSAT, cost per conversation, and escalation rate into a single view so you can see where the bot earns its keep and where it leaks value.
Chatguru is an open-source, RAG-powered chatbot platform built for commerce teams who need that measurement layer built in, not bolted on afterward. If you're ready to move from tracking to proving ROI, book a Chatguru demo with our AI Consulting team, explore how agentic commerce is turning chat into a storefront, and consider partnering with specialized AI development services to execute your roadmap.





