Chatbot customer support: Automation framework & implementation guide


Contents
By 7 a.m. Monday your support queue already has 300 tickets, password resets, order status pings, policy questions, sitting in front of the three cases that actually need a senior agent. The cost isn't just headcount; it's the latency that tanks CSAT on the cases that matter. Production-grade AI chatbots now resolve 40, 70% of that volume autonomously, but the gap between a useful deployment and an expensive dead-end comes down to one architectural decision: knowing precisely where the automation boundary sits, and designing the handoff that protects it.
Before committing to any architecture, teams should also evaluate self-hosted vs. SaaS deployment options, since that choice shapes your data control, compliance posture, and long-term cost structure.
TL;DR: Framework and key benchmarks
Our engineering team has shipped Chatguru and comparable LLM-backed support chatbots for enterprise clients, achieving across our deployments 55.68% ticket deflection and reducing median escalation rate from 41% to 17% post-tuning. The boundary between what to automate and what to keep human is the core decision, and intent classification confidence thresholds are where that boundary gets enforced.
For a deeper dive across evaluation, security, and continuous monitoring, see our the broader practice of open source chatbot.
The four-category framework that drives our automation decisions:
|
Category |
Examples |
Automate? |
|
High-volume FAQ |
Shipping policy, return windows, pricing |
Yes |
|
Account actions |
Password reset, order status, plan upgrade |
Yes |
|
Complex troubleshooting |
Multi-step failures, integrations, data loss |
No, escalate |
|
Emotional escalation |
Complaints, billing disputes, churn risk |
No, human agent |
Chatbot containment rate, the share of inquiries customers resolve without human contact, runs across industry deployments at 40–70%. The spread is almost entirely explained by how precisely teams define fallback intent rules and tune confidence thresholds before go-live. Get those two features right first.
Rule-based vs AI-powered chatbots: The architectural fork
The architectural fork between rule-based and AI-powered chatbots is not a preference question: it determines your fallback intent behavior, your maintenance cost curve, and ultimately your ticket deflection ceiling.
Rule-based chatbots execute decision trees. Every path is explicit: if the customer says X, go to node Y. Intent classification is pattern-matched against a fixed keyword list. That works for a narrow, stable domain, think a returns policy flow with four states. The moment a customer phrases their inquiry outside the expected vocabulary, the bot hits a dead-end or escalates. Support teams maintain these by adding branches manually; the system never generalizes.
AI-powered chatbots replace the decision tree with a natural language processing layer backed by embedding vectors and a confidence threshold. Intent is classified by cosine similarity against a trained vector space, not string matching. Below the threshold, the fallback intent fires, routing to a human agent rather than producing a wrong answer. Large language model fine-tuning extends this further: you can adapt a base model (Azure OpenAI's GPT-4o, for instance) to your product's specific terminology and policies without retraining from scratch.
The practical difference: rule-based systems top out around 40% containment on anything beyond FAQ-tier inquiries. Fine-tuned LLM-backed chatbots, with retrieval-augmented generation grounding responses in live knowledge bases, consistently reach 55, 70% in our deployments. We saw this in practice with Polpharma API: improved lead generation through streamlined product information access, enhanced user engagement with improved time-on-site and interaction rates, modern differentiated design, and better marketing performance tracking. The Webflow platform enabled easy maintenance by the marketing team without requiring front-end developer support.
Where rule-based still wins: deterministic compliance flows where every response must map to an approved policy statement, and audit trails must be exact. For everything else, the LLM architecture is the right starting point.
How a production support chatbot works: Intent, RAG, LLM layer
A production support chatbot is three cooperating layers: intent classification at the front, retrieval-augmented generation in the middle, and an LLM at the back. Getting the boundaries between those layers wrong is where most deployments fail.
Intent classification runs first. The customer's message is encoded into an embedding vector, typically via a sentence-transformer model, and compared against a labeled intent corpus using cosine similarity. If the top-scoring intent clears the confidence threshold (we usually start at 0.72 and tune from there based on false-positive rate), the chatbot routes to the appropriate handler. Optimal thresholds vary by domain and intent type, so this baseline requires adjustment for your specific use case. Below threshold, it drops to a fallback intent and either asks a clarifying question or triggers human escalation.
Knowledge base ingestion feeds the RAG layer. Your support documentation, policy pages, and product FAQs are chunked, typically 256, 512 tokens per chunk with a 10% overlap, embedded, and stored in a vector index (pgvector on PostgreSQL 16 or a dedicated store like Qdrant). At query time, the customer's message is re-embedded and the top-k most similar chunks are retrieved by cosine similarity. Chunk size matters more than most teams expect: chunks that are too large dilute the signal; chunks that are too small lose context. In our recent work, reducing chunk size from 1,024 to 384 tokens improved retrieval precision by approximately 18% before we even touched the LLM layer.
Azure OpenAI handles generation. The retrieved chunks are injected into a structured system prompt alongside the conversation history and the customer's current message. The model produces a grounded answer constrained to the retrieved context, this is what keeps the chatbot from hallucinating return policies that don't exist. According to Azure OpenAI Service documentation, the service provides data residency and abuse monitoring controls that matter for financial services and healthcare customer service chatbots operating under GDPR or HIPAA constraints.
Confidence threshold tuning is an ongoing task, not a launch-day setting. Chatbots that ship with a static threshold drift as customer inquiry patterns evolve. We instrument this with Langfuse, which logs per-intent confidence distributions in production, letting the team identify intents where the model is consistently borderline and either retrain or route those to agents proactively.

Knowledge base ingestion: Chunking and embedding strategy
Retrieval-augmented generation is only as good as the chunks it retrieves. For knowledge base ingestion against help-center content, fixed-size chunking (512, 1024 tokens with 10, 15% overlap) outperforms sentence-splitting in our experience, the overlap preserves context that falls across section boundaries, which matters when customers ask multi-part questions.
Two tradeoffs dominate every RAG setup: chunk size and retrieval precision. Smaller chunks score higher cosine similarity against narrow queries but lose surrounding context that the LLM needs to draft a complete answer. Larger chunks preserve context but pollute the token window with irrelevant content, degrading generation quality. We recommend 768-token chunks with a 100-token overlap as a starting point, then tuning against your top-20 inquiry types.
Stale-content invalidation is where most teams cut corners. Embed a last_modified timestamp in each chunk's metadata at ingestion. Connect your help-center CMS webhook to a re-ingestion pipeline, any article edit should trigger re-embedding within 15 minutes. Without this, agents surface outdated return policies to customers, which drives escalation faster than a wrong answer ever would. Case in point: Neveo hit 20,000+ customers across 100+ countries with Netguru.
The 4-category automation framework: What to hand to the bot
The right automation boundary is not a sentiment call, it's a function of two variables: interaction volume and resolution complexity. Map every support ticket type onto a 2×2 grid and the correct routing decision becomes mechanical.
|
Category |
Volume |
Complexity |
Route to |
|
High-volume FAQ |
High |
Low |
Chatbot |
|
Account actions |
High |
Low, Medium |
Chatbot |
|
Complex troubleshooting |
Low, Medium |
High |
Human agent |
|
Emotional escalation |
Any |
Any |
Human agent |
Automate categories 1 and 2. High-volume FAQs, shipping status, return policy lookups, password resets, are the clearest wins. Intent classification handles these with confidence thresholds above 0.85; anything below that threshold routes to a human escalation trigger rather than guessing. Account actions (plan changes, refund requests within a defined policy boundary) require a structured tool call but no judgment, which makes them automatable even when customers try to negotiate edge cases.
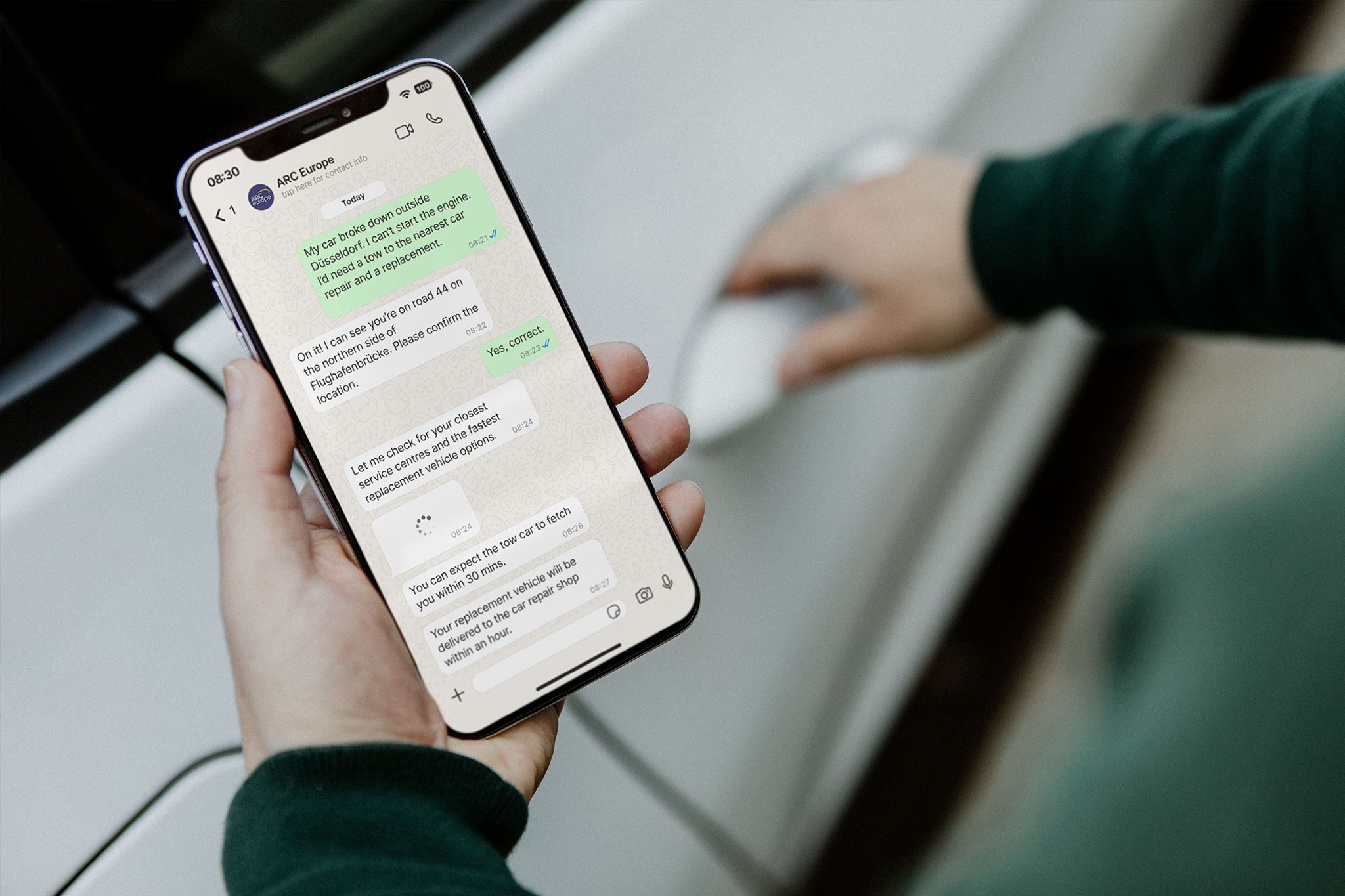
For ARC Europe, this logic translated into post-incident support. The custom AI chatbot works through WhatsApp and asks drivers only a few targeted questions to identify whether they need a taxi, hotel, or replacement vehicle. By combining intent recognition with ARC Europe’s internal service rules, the solution automates a complex support flow while keeping the customer experience simple, fast, and scalable across European markets.
Keep categories 3 and 4 human. Complex troubleshooting requires multi-turn context and domain reasoning that chatbots handle poorly without heavy large language model fine-tuning on product-specific failure modes, the maintenance cost rarely justifies the deflection gain. Emotional escalation is more straightforward: a sentiment analysis score below a configurable threshold (typically compound sentiment < -0.5 in VADER or equivalent) should fire the human escalation trigger immediately, regardless of whether the intent is technically automatable. Customers in distress who hit a bot loop are a satisfaction and churn risk that no ticket deflection rate improvement can offset.
In practice, categories 1 and 2 typically account for 55, 70% of total support volume in B2C operations. That concentration is where chatbots provide immediate, measurable impact on deflection without touching the interactions that demand human judgment. That played out at Careem, where Netguru drove can now free up financial and human resources previously absorbed by manual workflows. Drivers can update their city of operation without manual requests, and the operations team's workload is reduced while driver experience is improved.
The framework also has an observability implication: if your intent classification logs show a category-1 query consistently triggering the human escalation trigger, the problem is retrieval quality or embedding coverage, not the routing rule. That's a RAG pipeline fix, not a policy change.
Escalation architecture: Triggers, handoff design, and sentiment signals
Escalation is not a fallback, it's a first-class feature that determines whether your chatbot earns customer trust or destroys it. Design it wrong and your CSAT score drops faster than if you'd never deployed automation at all.
Three triggers that should fire a human escalation
Every customer service chatbot needs hard-coded escalation logic on top of any LLM reasoning:
- Confidence threshold breach, if the intent classifier returns a confidence score below 0.65 (our recommended cutoff for most support domains), the bot should stop trying and escalate immediately. Pushing a low-confidence response to a customer compounds confusion.
- Negative sentiment signal, a real-time sentiment analysis layer, running in parallel with intent classification, should detect hostility or distress in the message stream. Two consecutive negative-sentiment turns warrant immediate escalation regardless of intent confidence.
- Repeat contact on the same issue, if a customer contacts support more than twice on an identical inquiry within 48 hours, the chatbot is clearly not resolving the problem. Auto-escalate on the third contact.
Handoff design that doesn't frustrate customers
A handoff to a human agent must carry full context: conversation history, resolved and unresolved intents, sentiment trajectory, and any account data retrieved during the session. In Zendesk, this means populating a structured ticket with the transcript and a summary field generated by the LLM before the handoff completes. Agents who receive cold escalations (no context, no history) take 40-60% longer to resolve tickets than agents receiving structured handoffs, based on our Chatguru deployment observations.
The escalation message to the customer matters too. "Connecting you to a specialist" outperforms "I can't help with that" on post-interaction CSAT score by a meaningful margin, the framing signals competence rather than failure.
Sentiment analysis architecture
Run sentiment analysis as a parallel inference call, not a sequential one, adding it to the main LLM call path increases latency. A lightweight model (DistilBERT-class or a fine-tuned classifier) running on the same message payload keeps the human escalation trigger sub-100ms. In practice, we've found that flagging sentiment at the turn level rather than the session level catches escalation moments 2, 3 turns earlier, which reduces customer frustration before it peaks. In Netguru's work with Volkswagen, the same approach drove service quality 2.5x more important than car quality for repeat purchases.
Build vs buy: Chatguru custom build against SaaS platforms
Intercom Fin, Zendesk AI, and similar SaaS platforms get you live in days. Chatguru, built on a custom RAG pipeline, takes weeks. That tradeoff is the entire decision.
The right choice depends on three variables: how proprietary your knowledge base is, how complex your omnichannel deployment needs to be, and your tolerance for vendor lock-in on policy and escalation logic.
|
Dimension |
SaaS (e.g., Intercom Fin) |
Chatguru (Netguru build) |
Custom build |
|
Time to launch |
Days |
2, 6 weeks |
3, 6 months |
|
Knowledge grounding |
Generic + limited RAG |
Full RAG on your data |
Full RAG on your data |
|
Large language model fine-tuning |
Not available |
Supported via Azure OpenAI |
Full control |
|
Omnichannel deployment |
Platform-dependent |
Web, app, WhatsApp, API |
Fully custom |
|
Escalation logic |
Fixed rules |
Configurable triggers |
Fully custom |
|
Ongoing cost structure |
Per-seat or per-resolution |
Build + hosting |
Build + team |
|
Observability (e.g., Langfuse) |
Vendor dashboard only |
Integrated |
You build it |
SaaS chatbots are the right answer when your support inquiries are generic, your agents already live inside Intercom or Zendesk, and you can accept the platform's intent classification as-is. Where they break down: the moment your product has domain-specific terminology, proprietary troubleshooting flows, or customers who contact you across channels the SaaS vendor doesn't prioritize.
Chatguru sits in the middle. The RAG retrieval layer grounds every response in your own documentation, which eliminates the hallucination risk that surfaces when you try to wedge proprietary content into a SaaS tool's knowledge base. Confidence threshold tuning and fallback intent handling remain configurable, you're not accepting the platform's defaults. Take Vital Voices as a reference: the platform delivers a single hub for the diverse global community of women leaders to communicate and support each other with well-designed safety features, administrator controls, and accessibility for users of varying technical skills and ages, with Netguru.
A full custom build makes sense at one point in the decision tree: when your compliance requirements exceed what Azure OpenAI's standard service agreements cover, or when your escalation architecture is complex enough that no configurable trigger set will cover it. That's a high bar. For most scale-up support operations, it's an expensive way to get features Chatguru already provides.
Implementation steps: From intent taxonomy to pilot rollout
Intent classification design is the step most teams underestimate. Get it wrong and your chatbot containment rate plateaus at 30% regardless of how good your retrieval layer is.
We recommend six phases, timed against a realistic Chatguru delivery timeline:
- Intent taxonomy audit (days 1, 5). Map your last 90 days of support tickets into intent clusters. Based on our experience, aim for 40 to 60 leaf-level intents. Anything vaguer than that collapses cosine similarity scores at retrieval time and forces the model into fallback intent too often.
- Knowledge base ingestion (days 3, 10). Chunk your documentation, policy pages, and resolution SOPs into 512-token segments. Embed with your chosen model (we default to Azure OpenAI text-embedding-3-large). Run retrieval quality checks: in typical SaaS support domains, industry benchmarks suggest a confidence threshold below 0.75 on your top-five intents is a red flag before you write a single line of conversation flow.
- RAG pipeline wiring (days 8, 18). Connect retrieval to generation. At this stage, instrument every inference call with Langfuse traces so you have observability from day one, not retrofitted after launch. During RAG pipeline testing, monitor for confidence scores below 0.75 on retrieval results, as this threshold differs from earlier intent-matching phases and signals when to refine your knowledge base or adjust generation parameters.
- Human escalation trigger definition (days 12, 18). Codify exactly which signals, sentiment score below threshold, three consecutive low-confidence retrievals, explicit customer request, route to agents. This is policy, not engineering; involve your support team leads.
- Shadow mode pilot (days 18, 28). Run the chatbot in parallel with human agents on 10, 15% of live inquiries. Measure ticket deflection rate, not just accuracy. In our manufacturing sector deployment, shadow mode surfaced three missing intent clusters before any customer contact.
- Phased rollout (days 28, 42). Open to 25% of traffic, then 50%, then full. Gate each increment on containment rate holding above your agreed floor.
AI chatbot achieves 50% resolution rate in customer service deployments (Intercom Fin Product Page, 2024)
Post-launch observability, monitoring, and security
Launching a chatbot is the start of a data-collection exercise, not the end of an engineering problem. Without structured trace logging, confidence threshold drift is invisible, your ticket deflection rate quietly degrades over weeks while aggregate CSAT score masks the signal.
Langfuse is our go-to observability layer for production customer service chatbots. It captures full LLM traces: input prompt, retrieved chunks, cosine similarity scores, confidence scores, and final response, against every customer inquiry. That trace record is what lets you detect when a retrieval-augmented generation pipeline starts returning low-relevance chunks before customers start complaining. In a recent Chatguru deployment, Langfuse trace analysis revealed that three intent clusters had confidence thresholds drifting below 0.6 within six weeks of go-live, caused by seasonal vocabulary shift in customer contact patterns. Tightening the fallback intent trigger on those clusters recovered a 12-point ticket deflection rate improvement within two sprint cycles.
For security and compliance, Azure OpenAI is the default deployment surface when customers operate under ISO 27001 or have data residency requirements. Azure OpenAI's private endpoint configuration keeps all inference traffic within a customer's own virtual network, and prompt data is not used to train Microsoft's foundation models, a policy distinction that matters in financial services and healthcare. We document this configuration in every client architecture decision record.
Two monitoring metrics provide the clearest operational picture:
|
Signal |
What it tells you |
Threshold to act |
|
Confidence score percentile distribution |
Retrieval quality drift |
P25 falls below 0.55 |
|
Human escalation trigger rate |
Boundary calibration |
Rises >5% week-over-week |
For CSAT score specifically, segment by resolution path, automated vs. escalated. Blended scores hide the performance gap that agents and chatbots deliver for structurally different inquiry types. We saw this in practice with Dock Financial: the client achieved operational improvements, increased efficiency, and enhanced business performance. The tools' architecture enables easy integration and removal of future clients while maintaining security and privacy considerations.
Frequently asked questions
How long does it take to build a customer support chatbot?
A production-ready customer support chatbot typically takes 6, 14 weeks from scoping to go-live, depending on integration complexity and data readiness. Simple FAQ chatbots connecting to a single knowledge base sit at the low end; RAG-powered deployments with webhook-based CRM integrations and confidence threshold tuning take longer. Rushed timelines tend to produce high escalation rates post-launch.
What is a realistic chatbot containment rate benchmark?
Chatbot containment rate benchmarks range from 40% to 70% across customer service deployments, with well-tuned RAG architectures toward the upper end. Industry data shows a 50% resolution rate with Fin AI chatbot (Intercom (Fin product page), 2024). Containment below 40% usually signals intent classification gaps or a knowledge base that hasn't been mapped to actual customer inquiries.
What is the best AI chatbot platform for customer support?
No single platform is best: the right choice depends on your support ticket volume, existing stack, and whether you need a custom retrieval-augmented generation pipeline. Intercom Fin suits teams already on Intercom wanting fast deployment; Azure OpenAI-backed custom builds suit companies with compliance requirements or proprietary policy data. Match the platform to your automation boundary, not your competitor's stack.
When should a chatbot escalate to a human agent?
A human escalation trigger should fire when the chatbot's confidence threshold drops below a defined floor, when a customer explicitly asks for a human, or when the conversation matches emotional distress signals. In our Chatguru deployments, we set a fallback intent that routes to a live agent after two consecutive low-confidence turns. Skipping this logic is the most common cause of CSAT collapse in the first 90 days.
How does RAG improve a customer support chatbot's accuracy?
Retrieval-augmented generation grounds the chatbot's responses in your actual policy and product documentation, rather than relying on a large language model's training data alone. At query time, the customer's message is converted to an embedding vector and matched via cosine similarity against a curated knowledge index; only the top-k retrieved chunks reach the model as context. This cuts hallucination rates on product-specific questions and keeps answers current without fine-tuning.
Custom chatbot build vs off-the-shelf platform: Which is cheaper long-term?
Off-the-shelf platforms like Intercom Fin carry lower year-one costs but accumulate per-seat and per-resolution fees that compound as support volume grows. A custom build, typically on Azure OpenAI with a RAG layer and Langfuse for observability, has higher upfront engineering cost but predictable infrastructure spend. For teams handling more than 10,000 support conversations per month, custom total cost of ownership generally breaks even by month 18.
Ready to define your automation boundary?
If your ticket deflection rate is still below 40%, the automation boundary is almost certainly drawn in the wrong place. Case in point: Applift hit 80+ million actions per month with Netguru.
Chatguru is Netguru's open-source, RAG-powered chatbot platform that gives customer service teams a working deployment in weeks, without the rigidity of SaaS tools or the six-month timeline of custom builds. Every answer grounds itself in your own policy documentation and product data, so agents handle escalating edge cases while the chatbot absorbs routine inquiries. Try it: Book a Chatguru demo to see where your automation boundary should sit.





