This is What Your Product Infrastructure Should Look Like (UPDATED)

Most web applications are fundamentally similar – they get input from users then process and store it. The end result usually shows the processed input to users in the form of an output.
These applications are usually called CRUDs – this means that the infrastructure (the core components that work together) needed to support a typical product can stay almost the same for most startups.
This article will show you the core components and how to design your infrastructure in a way that it is efficient, scalable and cost-effective.
The Core Components
Here are the elements that most web applications need:
Web Server
This is a place where the code is executed – there are many options to choose from and going with one of the cloud web service providers, such as Microsoft (Azure VM) or Amazon (EC2), is normally a safe choice.
They are well-supported, easy to use and when your product grows, it's easy enough to migrate to a faster option from the same provider.
Application Dependency Manager
The dependencies of the application such as the background processing worker, cache database, HTTP server etc, have to be managed.
You can either do it manually which can be erroneous and not easily scalable and upgradable or use containers, usually in the form of Docker containers, which is a bit harder at the beginning but, in the long-run, more cost-effective.
When using containers, you can think of dependencies as black boxes with clearly defined rules of cooperation.
Application code
It may be obvious but it's still worth remembering that the code itself needs a programming language interpreter or virtual machine.
The environment that the code needs (like Ruby or Node.js) is a major factor when choosing the web server as some technologies like Ruby are more platform-agnostic (you can run them almost everywhere) and some are usually working better on a particular platform - like .NET.
Looking to scale your app? Download 12 tips from the experts:
Database
There are two major choices on where to store your data:
Should the database be on the same machine as the application?
I’d argue that it shouldn’t – the effective configuration of the machine for a web server and a database are different, but the major reason is that it's hard to beat the quality of a solution designed specifically for databases like Amazon RDS and Azure SQL.
These machines are managed by some of the best experts in DB administration – if you can afford them, which is extremely realistic, do it now.
They allow you to scale performance as needed and create backups just by changing settings in the dashboard. Using the same server to host a database makes the application more prone to data loss in case of a server failure. Safety-wise, a database should always be stored on a separate machine or service.
Should you use a relational or non-relational database?
In order not to start a flame war, I’d say that the data in most applications can be organised in one or more tables, or "relations", of columns and rows.
Accordingly, choosing a relational database as a default one is usually a safe choice. Using a non-relational database should be backed by research to see if it's a good choice for the particular use case.
Let's look at some of the pros and cons:
Pros of using a relational database
If you are working with structured data, such as transactional data, a relational database is the preferred choice. In addition, most are ACID (Atomicity, Consistency, Isolation, Durability) compliant, which means that the integrity of your data is guaranteed.
Cons of using a relational database
As with any database, relational databases require that the architecture is carefully developed before the data is added. No matter if you use relational or non-relational DB, the structure of the data will require changes. Be aware that relational databases are not best suited to store 'documents' i.e. objects that have a structure already and are complete within themselves and do not require any sophisticated relations/indexes/views, so in this case the use of a non-SQL database engine may be a better.
Now let's look at the aspects a non-relational database:
Pros of using a non-relational database
If you are working with specific types of data, a non-relational, or NoSQL database is your first choice. It is able to process any data type without the need to modify the architecture. This means that it takes much less time to create and maintain this type of database.
Cons of using a non-relational database
The flexibility of being able to handle many data types does mean that you’ll pay with extra processing efforts. In addition, the administration of a NoSQL database is more complex.
Background Processing Worker
A place where all calculations that take more than a second to complete are processed.
You can think about it like this: without a background processing worker, any calculation that is done in the application requires someone looking at the spinning circle in their browser, waiting for the page to load while it is being calculated – you don’t want that for calculations that take more than a second.
Should I have the background processing worker on a different machine than the application?
Probably yes, but you can start by having it on the same machine because the migration, when needed, will be easy if you’re using Docker.
Database
Nowadays, databases are fast – but for the data that doesn’t have to be stored persistently, it's a good idea to store it in the memory.
Random Access Memory (RAM) takes nanoseconds to read from or write to, while hard drive access speed is measured in milliseconds. Other than the persistency problem, RAM is more expensive than hard disks. That’s why only some of the data is stored in-memory. Whenever data doesn’t need to be persistent, store it in the memory. This greatly improves the speed of the application.
You can host an in-memory database like Redis on the server where you have your application – when your application outgrows this solution, it's very easy to switch to external services like AWS ElastiCache.
Email Delivery Service
Email delivery is hard. Outsourcing the problem is the most cost-effective solution.
It’s not expensive and the time saved can be spent doing more valuable things. Not only will you have your emails delivered, but you will also get a lot of useful statistics.
You will also avoid potential address/domain blacklisting should your email look like spam – instead, use external services like SendGrid or Mailgun.
First, let's check out SendGrid:
Pros of SendGrid
SendGrid offers access to a range of analytics and useful reports, including email delivery rates and visibility on which emails have been filtered out as spam. It’s also great for beginners as it is simple to set up, plus SendGrid provides a wealth of helpful resources such as instructional videos and guides, along with a highly rated customer support team.
Cons of SendGrid
There are few major drawbacks to using SendGrid, though some users have highlighted an issue with the lack of a sandbox, or test mode that has the ability to send real emails. This means that it is not possible to check integration with SendGrid during development, without the use of real credentials which you may not want to distribute to your development team.
Let's look at Mailgun:
Pros of Mailgun
Mailgun offers a generous entry-level tier on their pricing plans, which allows users to send up to 10,000 emails per month free. Advanced analytics allow you to track engagement metrics like open and click-through rates, along with detailed logs that make spotting and correcting issues easy.
Cons of Mailgun
The initial setup and configuration is quite comprehensive and offers a lot of options and the advanced analytics Mailgun offers need proper 'tags' to get the most of out of their data.
Storage Server
If you need to store a lot of static files using a dedicated storage server is a must – it will be cheaper and faster for your users.
Let your web server handle business logic and storage server handle delivery of static files. Using solutions like AWS S3 or Azure Blobs will also come with the benefit of having a backup for the files – these solutions are incredibly cheap and guarantee 99.999999% SLA.
Content Delivery Network
Most startups need one or two web servers to handle traffic – but even if the web servers are fast, the data still needs to travel over the wires to the users.
That’s why it is important to have a CDN that will help, almost automatically and without much configuration, to serve most of the content to a user based on their geographic location. This will also help your product survive attacks like DDoS – the most common solutions include Cloudflare and AWS Cloudfront.
Let's look at the pros and cons of Cloudflare:
Pros of Cloudflare
Cloudflare benefits from a large number of data centers worldwide, with a wide geographic distribution. It can be integrated with all hosting platforms, and all plans, including the free plan, offers excellent security features including the ability to block DDoS and DoS attacks.
Cons of Cloudflare
One area where Cloudflare is lacking, is that it only offers a push CDN service. This places the onus on you for checking that your content is being delivered to Cloudflare’s data centers when any changes are made.
To compare that with Cloudfront:
Pros of AWS Cloudfront
If you are already storing content with Amazon Web Services, CloudFront is ideal as it integrates seamlessly with AWS, requiring virtually no setup. In addition, there is no minimum fee for premium plans, you only pay for what you use.
Cons of AWS Cloudfront
There are no major disadvantages to using AWS Cloudfront, although technical support is not included in the cost of the service. If you want any help beyond access to their community forum, you will need to pay extra.
Logging
This a very wide topic but back in the day, there was a log file (or files) stored on the server and accessed only by connecting to the server.
Nowadays, we have so many logging tools that you can, and should, log pretty much everything. When using multiple machines it's worth aggregating logs to some centralised tool in order to browse through them with ease such as PaperTrail, Logmatic or ELK Stack.
Error tracking software
The first thing is to know whether the users that access a web application have any problems.
A service like Rollbar can be easily integrated into the application and catch as well as notify you whenever errors occur – adding an application analysis tool, like NewRelic, will help you to find bottlenecks within your application.
It’s crucial not only to record your application’s logs but also server’s logs. Ideally, a service that aggregates all logs can also do automatic analysis of the data to notify you whenever unexpected events take place.
Having a good logging infrastructure will not only notify you about a potential or existing problem, but also considerably decrease the time needed to fix it.
Connecting the components
Having so many components may seem complicated at first, but in reality for an experienced person it can be implemented within 2 days, or even a couple of hours.
Using many external tools isn’t necessarily more expensive than trying to do everything yourself.
Here’s a draft of the infrastructure that uses services which we think are the best for most case scenarios.
You may or may not need some of the components included – it's a draft of infrastructure that will suit most products because it's not only cost-effective but also can scale when your product grows.
If your product is not a typical CRUD application or has any special needs, this is an excellent starting point to adjust the infrastructure further to suit the exact requirements of your product.
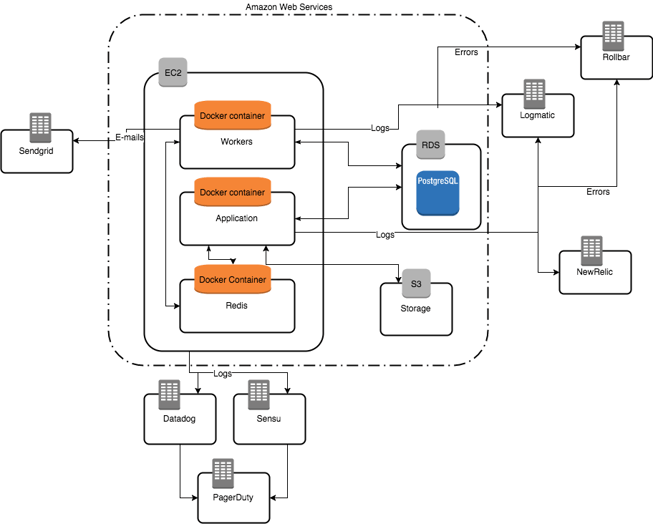
You can:
- Change particular providers for others.
- Add additional web servers – in that case you’ll also need a load balancer and potentially an autoscaling mechanism, or an additional database.
You know your infrastructure is well planned out if you can easily change a part of it without changing the whole concept.
At Netguru, we use a similar infrastructure in most applications and it has proved to be an excellent framework to start with and expand on later.
If you would like help from the experts find out more about our web development services today.





