How To Autoscale Your Kubernetes Deployment?


When it comes to cloud computing, there are a variety of options that come in handy in terms of scalability.
One of them is the autoscaling mechanism provided by the leading containerized orchestration platform – Kubernetes.
Imagine a situation where there is no automated mechanism implemented, and any change in demand is not taken into consideration by an application or underlying infrastructure, so it needs manual intervention.
Such a solution wouldn’t survive in our digitized world, and the lack of automated scaling would have an impact on resource utilization and costs, and in general on the reception of your application. In such a case, you will probably be paying more for an infrastructure running at peak capacity all the time to maintain availability. Otherwise, your application may not be fully available during peak hours, consequently losing clients and money.
That’s why autoscaling is such an important cloud concept and where Kubernetes comes in with its autoscaling capabilities to help us solve these problems. In this article, we will dive into how we can leverage Kubernetes autoscaling methods to fulfil our scalability requirements when it comes to containerized applications.
What is autoscaling in Kubernetes?
Kubernetes is an open-source containerized orchestration platform and, as such, comes with lots of automation features and capabilities. One of these features is autoscaling. Kubernetes autoscaling is a mechanism that helps engineers with an automated and convenient way to provision and scale resources based on specific demands.
Imagine that your application becomes a great success and grows faster than expected. Leaving it as it is will have an impact on availability and end users’ feedback.
Such a situation can be mitigated with the Kubernetes autoscaling mechanism, so when there is more traffic than expected, Kubernetes can automatically add more pods, adjust pods’ average CPU utilization and memory, or update the number of cluster nodes without any disruption of availability. Wondering how it works?
Instead of manual intervention based on configured demands, Kubernetes will dynamically/automatically scale up pods or nodes according to the needs and scale down when additional resources are no longer needed. It helps with using resources in the most optimal way, consequently reducing the cost of the underlying infrastructure.
When it comes to autoscaling in Kubernetes, we can distinguish two layers on which scaling can happen: the cluster layer and pod layer, both being fundamentals of Kubernetes architecture.
As a part of the pod layer, we can distinguish two Kubernetes autoscaling methods.
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler (HPA) automatically updates Kubernetes resources such as a Deployment by deploying more pods as a response to increased demands.
Just as an engineer configures the number of min and max pods, Kubernetes will handle horizontal pod autoscaling between these numbers based on, for example, target CPU utilization.
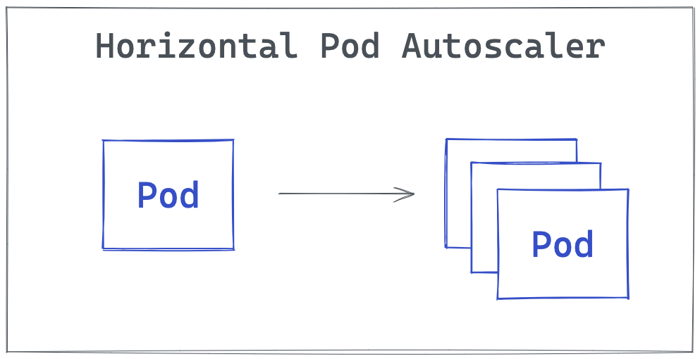
It is worth mentioning that a common way to use HPA is to configure scaling based on CPU/memory custom metrics. The limitation of HPA is that it can’t be applied to resources that can’t be scaled, i.e., DeamonSets.
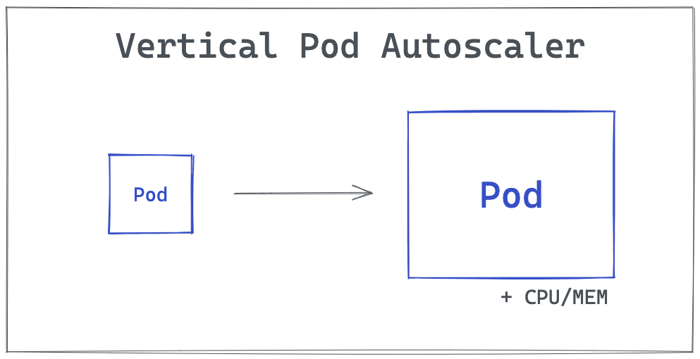
Vertical Pod Autoscaler
Vertical Pod Autoscaler (VPA) automatically updates the amount of CPU and memory requested by pods running in clusters as a response to increased demand.
The difference between vertical and horizontal scaling is that horizontally we add new identical pods, and vertically we add more resources such as CPU and memory to already existing pods.
Scaling clusters is possible by using another tool described below.
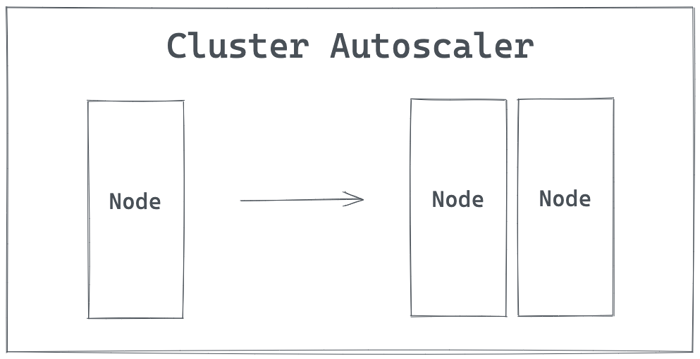
Cluster Autoscaler (CA)
Cluster Autoscaler (CA) automatically updates the size of a Kubernetes cluster by adding or removing nodes, so that there are no unscheduled pods because of lack of resources, and on the other hand, there are no unneeded/underutilized nodes.
The first two autoscaling methods are available no matter if we are talking about cloud computing or on-premises computing.
But when it comes to scaling the cluster itself, we can really leverage the elasticity of cloud computing where we can fire up additional resources in a few clicks. That makes the Cluster Autoscaler a really powerful tool in terms of scaling. Below we will dive into the details of how the CA works.
How does Cluster Autoscaler work?
Cluster Autoscaler, as a part of the Kubernetes autoscaling mechanism, is a tool that automatically adjusts the size of the Kubernetes cluster when one of the below conditions takes place:
- Due to insufficient resources, there are pods that can’t be scheduled on the cluster and are left in a “pending” state.
- Some nodes in the cluster are underutilized, and pods running on these nodes can be rescheduled to other nodes.
Imagine a situation where horizontal or vertical pod autoscaling is configured, but peak demand is so high that the current cluster efficiency/infrastructure is not enough to handle more pods or pods with higher resource utilization requests.
You would end up in a situation as if the autoscaling wasn’t configured at all, and manual intervention would be needed to scale up cluster size by adding compute units/nodes.
That is why Cluster Autoscaler is such an important part of Kubernetes autoscaling capabilities supported on Kubernetes platforms provided by the major cloud providers: Microsoft Azure, Amazon Web Services (AWS), Google Cloud Platform (GCP), and many more.
Cluster Autoscaler checks periodically for pods that are unable to be scheduled due to a lack of resources and makes a decision to add an additional node from the node pool to the cluster.
Moreover, when the request utilization falls below a certain percentage, Cluster Autoscaler makes a decision about removing nodes from the cluster, consequently optimizing resource usage.
One term here that needs an additional explanation is a node pool. A node pool is a set of nodes of identical size. Cluster Autoscaler by default, adds all nodes from a single node pool, resulting in a cluster where all nodes have the same size.
For example, Azure Kubernetes Services comes with the capability to configure multiple node pools with attached unique autoscaling rules. Enabling both of these features allows us to build a scalable cluster consisting of different compute sizes.
Can Kubernetes scale nodes?
As described above, one of the three methods of autoscaling in Kubernetes is Cluster Autoscaler. With its capabilities, it is possible to dynamically add and remove nodes from the cluster based on configured rules and demands.
So when there is more load than expected, and the application has no space to be scaled out, Cluster Autoscaler will add a new node to the cluster to make room for new pods to be scheduled.
Tips and reminders for autoscaling in Kubernetes
There are a few things that are worth having in mind when it comes to autoscaling in Kubernetes:
- Always choose the right autoscale solution for your application, spend time on fine-tuning your autoscaling configuration – it does not bring any value if autoscalers are configured with demands or rules that will never come true.
- Leverage using autoscalers together – while it is not recommended to use VPA and HPA on the same metrics, it can be powerful, i.e., to use VPA based on CPU utilization and HPA on custom/external resource metrics. In terms of resource usage optimization, it might be powerful to use Cluster Autoscaler with HPA/VPA.
- While Cluster Autoscaler sending a request to add a node to the Cloud Provider API can take up to 60 seconds, it might take several minutes in total for new compute resource requests to be provisioned to the cluster and schedule pending pods on it. Be aware that scaling up the cluster may take some time.
- Cluster Autoscaler is available mostly on managed Kubernetes platforms provided by major cloud providers. Its availability on on-premise clusters is limited by underlying infrastructure and used solutions. Cloud computing, in that case, gives us much more elasticity when it comes to requesting new compute units and adjusting the cluster.
Key takeaways of Kubernetes autoscaling
Autoscaling in Kubernetes is a key feature of building modern containerized applications where scalability and reliability are taken seriously. Kubernetes comes with three different components that can be used to autoscale your deployment. But there is more.
We can integrate other open-source autoscaling solutions that even extend capabilities available in Kubernetes, such as KEDA – Kubernetes Event-Driven Autoscaler – and Karpenter. In a modern digital world where milliseconds of application downtime can create mayhem, it is really important to choose the right scaling solution.
With Kubernetes as a container orchestration platform, most of that task of choosing the right solution is solved for us. No matter which approach we choose, in the end we can be sure that Kubernetes autoscalers will do the job and our containerized application will be reliable and scalable.












