On-Device Training with Core ML - Make Your Pancakes Healthy Again!


The first time I heard about it I became extremely excited and couldn’t wait to dive into the research. However, life is life and it took me 10 months to actually do it. In this blog post I would like to invite you on a machine learning journey with me. We’ll start from an overall review of the feature, then take a quick look at the pros and cons, and of course try it ourselves! Let’s start 🚘
What does on-device training actually mean?
Let’s look at an example, an application I’ve created for my Create ML journey - the HealthyLuncher app. It classifies your lunch as healthy or fast food. I have a tradition - every Sunday I make pancakes. What do you think when you hear “pancakes”? I bet it’s “sweet”, “sugar”, “flour”, “fried”, in a word - unhealthy. But this is not the case here. I love healthy food and switching ingredients for more nutritious options. My pancakes always have some weird flour in it instead of plain and bananas instead of sweeteners. Crazy, I know. The thing is that the machine learning model sees pancakes the same way most people do - not green, fried, sometimes with chocolate. The model returns a high probability that they are fast food, even though in my case I know they are very healthy. And here comes on-device personalization to our rescue! 🎉
We are going to tailor those results according to my case, that of healthy pancakes. This will be done in the training section but is a great example of a good use case for this feature. “Healthy” can be a different thing to different people and each person can use machine learning to consider those things in the same way.
Actually, the terms that Apple uses is “on-device personalization” instead of “on-device training”. We should look at this as at adding slight changes to the existing machine learning model. The changes are made personally for the user and tailored to their data. Training from scratch on the device would be too much. Usually, such training is run on separate servers for a huge amount of time. So, the model we want to use for this case should already be working fine or at least be pre-trained with some relevant data.
It’s also worth emphasizing that it’s more about doing some small improvements for one model personally for each user than about gathering feedback from different users and improving the model overall. We are tweaking some model behaviour for each user personally on each device and each model is going to be different.
Why is it worth using?
- Privacy
The model never leaves the device. We do not need to send data anywhere for retraining. The user can be sure that their privacy is ensured. - No need for a server
We do not need to find and pay for a server. - No need for an Internet connection
Everything is done offline on the device.
If you think about it, these are the same pros that Core ML has. So, using this feature for personalizing the model will let you take advantage of them.
What to consider before using it?
- Backing up the model
The model stays on the device, which is great. However, what if the user deletes the app and reinstalls later? They will lose the new version of the model unless we take care of that by sending it somewhere and later downloading it. - Adding a new version of the model
If the model stays and retrains on a device, what if we want to change it for a new model, let’s say an improved one (not personalized)? If we do that, the user will also lose all the personalized parts of the model and will need to start from scratch. - iOS 13+
Updatable models will work only for devices running iOS 13 or higher. Usually we support those earlier versions too. - Machine learning limitations
Only two types of models can be marked as updatable: - k-Nearest Neighbor (k-NN)
- Neural Network (NN)
When it comes to NN, there are more limitations as for which layers can be marked as updatable and which loss function or optimizer can be used.
Disclaimer: While writing this disclaimer the first thing I remembered are phrases like: “You should not attempt these exercises without first consulting your doctor.”. Well, I wanted to emphasize here just in the same way the machine learning thing. If you want to create a highly effective machine learning model and use it in a production-ready application, the whole blog post should be revised. Everything here is presented for educational purposes and real use cases are usually much more complex.
How do we enable training on the device?
First things first - we need a model of one of the above-mentioned types. Then we can use coremltools to convert it to a .mlmodel file and mark it as updatable. In the case of Neural Networks we should choose the exact layers that should be marked as updatable, which means the ones that will be retrained. Usually, you would want to only mark the last ones as such, but it depends on the neural network architecture used. The whole retraining process would too much for a phone. The model should also have a loss function, an optimizer, and parameters such as the number of epochs.
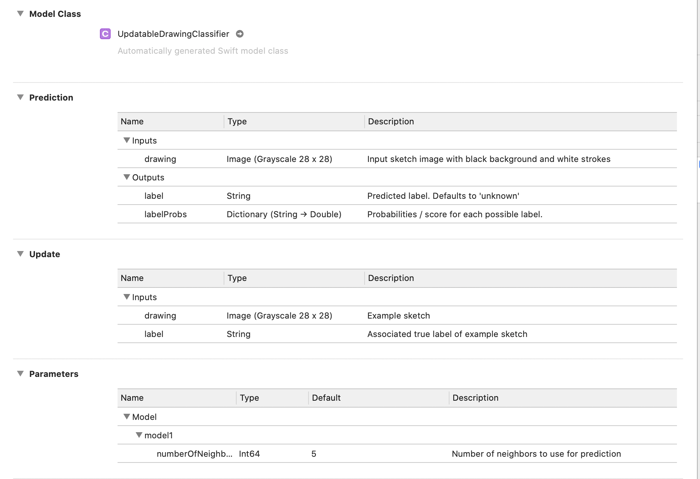
There is one updatable model that we can download on Apple’s site - UpdatableDrawingClassier. It takes a drawing (an image) as an input and returns a label for it.
Coremltools offer a set of example scripts which you can run and create an updatable model.
The updatable model in Xcode will have new sections: Update and Parameters.
k-Nearest Neighbor vs Neural Network
Oops, did I just say that I wouldn’t be going in depth into ML topics? Well, I think it is a must to address the difference between these two and which one to choose, even if you are only experimenting. k-NN is generally simpler and easier to train, no matter if we are talking about a mobile device or not, because it’s basically about memorizing data rather than learning. However, neural networks are more powerful and can grant us better results. k-NN requires few training examples per class and it’s relatively easy to constantly add a new number of classes. NN needs a lot of data per class for training and you need to add those at the beginning. Adding classes on the go is usually not a great idea as it would require you to retrain the whole model.
For example, if we would like to add one more label to our healthy lunch model, let’s say to add “pancakes” to those “healthy” and “fast food” labels, in the k-NN case it’s not a problem, while with NNs it’s harder to do.
On it’s presentation WWDC video Apple shows an example of a k-NN updatable usage model. In the next section we will go quickly through it. However, for testing NN usage, I’ve created a brand new model for the HealthyLuncher app.
Let’s take a look on k-Nearest Neighbor case
For this one I’ve just downloaded the ready to use UpdatableDrawingClassier model. I decided to create my own app with that. I won’t be attaching code in this case. Apple has released their PersonalStickers app along with documentation for the whole process, which they presented at WWDC, where you can see how everything is done. The app replaces the user’s drawings with emojis which the user has previously defined, so with which they taught the model.
Briefly, the updating process consists of the following steps:
- Wrap your data.
In the example app the user should draw three images and choose one emoji. That data should be firstly wrapped up to MLFeatureValue, then to MLFeatureProvider, and the last step - initialize the MLBatchProvider with it.
[MLFeatureValue] -> [ MLFeatureProvider] -> MLBatchProvider - Create an update task.
To the update task we send the previously created MLBatchProvider and the location of the compiled model we would like to update in the .mlmodelc format - this is crucial. The MLUpdatedTask can update only compiled models (in the .mlmodelc format).MLUpdateTask(forModelAt: URL, trainingData: MLBatchProvider, configuration: MLModelConfiguration?, completionHandler: (MLUpdateContext) -> Void)
We also can pass any additional configuration and a completion handler which will be called when training is finished. - Run the update task.
To run the update task we should call
and then Core ML will run this task in a separate thread in order to train the model.updateTask.resume() - Save the new updated model.
When the
is called, we need to save the new updated model to a temporary location and then replace the previously updated model with the new one.completionHandler: (MLUpdateContext) -> Void) - Load the updated model.
The last step would be to load the new model with the help of the model’s
initializer.init(contentsOf:) - Use the updated model for predictions 🎉
That’s all! The process is really not that complex and Core ML handles a lot of things for us :)
Neural Network and, finally, pancakes!
Creating a model
First of all, I need to create a new model. Unfortunately, I couldn’t use the model created with CreateML, because it cannot be marked as updatable. So, I needed to create one with Python. I used the same data for creating it as for the Create ML one. You can read more about this in Create ML blog post in the Images -> Data Preparation section. I chose at the end to use TuriCreate to create an image classifier. I found it the easiest way to create a model for non-ML experts. Then, I used coremltools to make that model updatable and marked the last layer as updatable. I went with the SDG optimizer and the Categorical Cross Entropy loss function. The script I used can be found here. I can say that I chose those options quite randomly. I think now you understand even better why I put that disclaimer at the beginning. However, everything worked. My model is classifying my lunches in the expected way. It classifies salad as healthy and burgers as fast food. Obviously, pancakes are fast food, too, but not for long.
Updating the UI
Let’s start from the UI perspective. I’ve decided to start from the simplest things and added a “Retrain button” near the “Open” one. It appears just after we open a photo in case the model will return a label which we consider incorrect. We have only two cases, that’s why retraining here means just adding the chosen photo to the update task with the opposite label to the one model has returned. Ideally you would add a feature with a possibility of choosing multiple images for improving one label. In that way, I could add all my pancakes I’ve ever cooked at once or at least at batches of fixed size. One photo is not enough for retraining the whole model but for trivial test training with one image at a time it turned out successful. I’ve also added a “Reset model” button in the top right corner, so that we can reset the model to the initial state before any updates are made.
Training model logic
The update logic is almost the same as in the k-NN example. We just will use another initializer here.
init(forModelAt modelURL: URL,
trainingData: MLBatchProvider,
configuration: MLModelConfiguration?,
progressHandlers: MLUpdateProgressHandlers)Here we can track the progress of each step in training, one of which is trainingEnded, where we can save the updated model. I’ve used the simplest configuration and the simplest training process possible. You can see the detailed implementation in the ImageClassificationService class in the HealthyLuncher repository.
Background training
However, if we would create a more complex training, probably the best idea would be to train it in the background. For that purpose the best solution would be to use the BackgroundTasks framework. In that way you can schedule your MLUpdateTask to run and wake up the app at a specific time in the background.
Memory leak
While training the model it is easy to notice one thing - a memory leak. Each time I created an MLUpdateTask it added around 250 MB and never released it. Instruments show that it’s Core ML holding that memory, there also are open bugs on that topic, and people do mention it. Maybe I am still missing something that was not written down in the documentation which would mitigate the problem. For now, I don’t think there is a solution.
Let’s check how it works
Anyway, let’s check how it works! I’ve uploaded a typical salad and burger pictures for a start. The classification works as expected - healthy and fast food, respectively. Well, it’s time to try this out with my favorite pancakes andddd…. Yikes, it’s fast food! Just as I thought. I’m hitting the “Retrain” button. If you try to predict the result on the same picture again you'll most probably see that it’s still fast food. Weird, right? However, the thing is that underneath the prediction did change actually. You can check the result in the app printing logs. For example, it can be that at the start our model was sure 95% it’s fast food and later that prediction would be dropped to 85%. This is expected behaviour and means that our updating is working, so we can continue doing this.
The next thing I do is retraining using similar pictures of pancakes and at the end the model returns “healthy” even for that starter initial picture. It works! The app is now tailored for my personal choice of healthy food.
After hitting the “Restart model” button and the model coming back to the initial state my pancakes become fast food again.
To sum up
On-device training is an exciting new feature which enables us to personalize a machine learning model for each user. It guarantees privacy and there is no need for a server for that purpose. The training is done in an easy and convenient way as Core ML handles most of the things for us. However, it has its own limitations: those of machine learning ones and also the fact that it can be used only on iOS 13+ devices.
Thanks for going on this machine learning journey with me, see you next time!
Useful materials
- On-device personalization Apple documentation
- On-device training with Core ML series by Matthijs Hollemans - a great very deep dive into the topic













