So AWS Went Down. Here’s How You Can be Prepared If It Happens Again


Many websites went down for a few of hours, some of us couldn’t even continue working on your projects due to the outages of services like CircleCI.
Let me give you a quick recap, if don’t know what I’m talking about. Amazon’s S3 web-based storage service was experiencing widespread issues, leading to the service being either partially or fully broken on websites, apps and devices upon which it relies.
There’s one essential misconception about what happened. Everybody is saying “AWS is down”, but in fact, only 1 out of 14 regions went down. Your services were only affected if your infrastructure is based in the us-east-1 region. What can you do to prepare for the next outage?
1. Active-Active or Active-Passive Failover on Route53
The term Active-Active is not AWS specific and relates to “high-availability”. Basically, it means that the traffic intended for the failed node is either passed onto a working node or load-balanced across the remaining nodes. In our case, the failed “node” might be a whole region or the whole AZ. This approach is somewhat expensive because it requires you to have a full copy of your infrastructure in another region.
The Active-Passive approach is a bit of a cheaper solution. Fully redundant instances are only brought online when their associated primary node fails. Note that this approach also comes with extra time overhead to provision and warm-up your servers.
Luckily, AWS provides a very handy tool to detect this type of failures and automatically re-route whole traffic. It’s called Route53, and by definition, it’s a scalable cloud Domain Name System (DNS) but also comes with some additional features.
Two additional features I’m talking about are “Health Checks” and “Traffic Policies”. We use them often at Netguru. Once Health Check detects that your endpoint is unreachable, it will start routing traffic to a failover endpoint/node.
Configuring such a scheme is fairly simple:
1. Go to Route53 -> Health Checks -> Create health check
2. You should see the following screen:
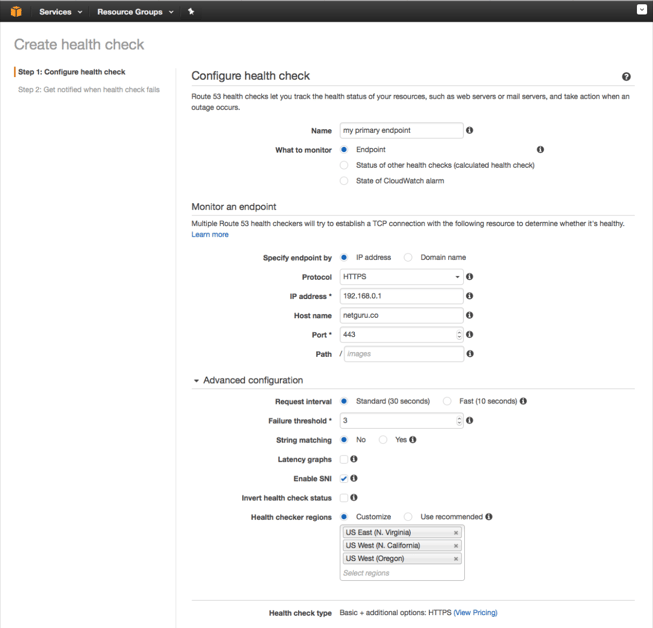
In the example above, I’m checking if netguru.com is up and running. If three consecutive health checks performed every 30 seconds fail, it should report failure.
3. The second piece of our scheme is the policy. Go to Route53 -> Traffic Policies and create a new policy.
4. Creating a policy is pretty straightforward. All we need to do is add a Failover Rule and add primary and secondary endpoints, like so:
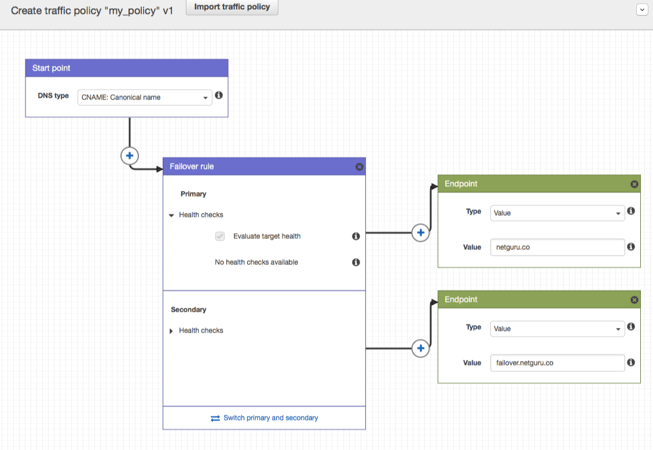
During the next outage, all your traffic should be redirected to an unaffected node automatically, without your supervision or need to issue explicit commands.
2. Cross-region assets replication
If you aren’t going to use an Active-Active/Passive configuration, you can still use automatic asset replication. Once enabled, every object uploaded to a particular S3 bucket is automatically replicated to a designated destination bucket located in a different AWS region. This is particularly useful in cases similar to the recent outage.
Enabling this feature is also very easy and might save you a lot of money.
1. Head to the bucket that you’d like to replicate
2. Go to Properties. Before enabling cross-region replication, you have to enable Versioning first.
3. Once you’ve done that, you would also need to adjust how your app serves static content. The quickest solution is to write the S3 assets’ hostname (from http://mybucket.s3.amazonaws.com to http://my-backup-bucket.s3.amazonaws.com) in case a particular CloudWatch alarm (in our case, the one associated with health checks) is on.
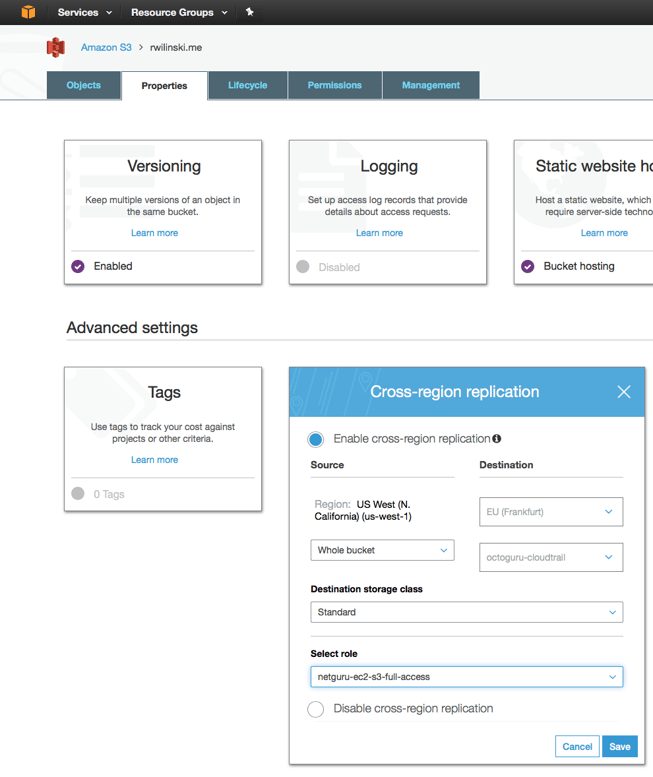
In conclusion, there indeed are a few things you can do yourself to mitigate such a big outage as the recent one. In other, not so serious cases, things like Multi-AZ deployments should be enough.


















%20_HD.jpg?width=384&height=202&name=DSC_7814%20(1)%20_HD.jpg)








