What's Pull Request Flow All About? A PM's Perspective


But now it’s time to explain it for those of you who do not necessarily code each day. Let’s go!
What is Pull Request flow
Pull Request flow is one of GitHub’s possible Software Development flows.
Long story short - you have 4 basic flows to choose from:
- Centralized
- Feature Branch
- Gitflow
- Forking
We will focus only on Centralized (Master) and Feature Branch only as these are the two we know the most about and we have plenty of practical experience with them. Centralized (Master) flow basically means that you push all commits directly to Master.
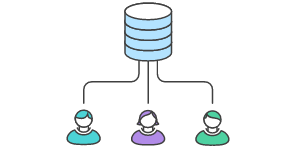
Sounds easy, right? Maybe it is - but we didn’t quite like it.
‘Am I synced with master?’ This was one of the most common questions each developer asked themselves before pushing a commit. Centralized flow focuses on one branch of the code being edited by multiple developers at the same time. This means that each commit pushed from the local environment must be predated by a master sync so that you’re 100% sure no changes were made to it while you were coding.
Wait? What? What do you mean?
Imagine building a house and several workers are involved. Each of them creates their part of the work separately and then they combine the results into one, fully functional house. The tricky part is that they don’t see the results of each other's work all the time - they need to sync their blueprints with the results of what has already been done (syncing to Master).
So if one of them delivers, say, the window frames and merges this change, his buddy working on the glass must first clone the updated result (new Master branch) and then deliver his part (hoping no changes were made along the way and his blueprints are still up to date).
This means their commits may be out of date with the initial Master branch when they try to push their changes, and, indeed, most definitely will be if the team has more than two developers.
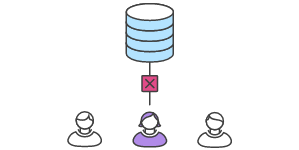
So, as you see, each subsequent developer will be out of date when delivering his tasks because the Master branch is changing with each commit.
What’s more, we were able to control only individual commits. You know how important quality is to us and we had to put a lot of effort into understanding what each commit relates to and how it will impact the whole codebase.
There has to be a better, faster way! We wanted to be faster while improving the quality of our code even further. The result was a revolution in our flow. It wasn’t easy and many hours were spent on discussing all the pros and cons. But, finally: here it is. We have switched to Feature Branch (Pull Request) flow. OK, great, but what does this mean?
Feature Branch flow
The Master branch is still the most important, and it still represents the official code base of the project. The difference is that we do not need to sync it after each commit. Now we can create a separate branch for each feature we are working on and can play with it as much and as long as we want without being worried about what our buddies are up to. We’re not getting in each other’s way with pushing the code. Ultimately, we only see the final version of the feature without any of the changes that were made along the way.
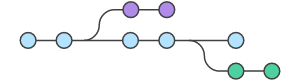
Sure, we need to be in sync with Master before we push, but not for each individual commit. We can sync once for all commits related to the feature we are working on. Each commit does not create a new Master - it’s added to the existing one and updates it.
To keep it as simple as possible imagine this: you’re working on the aforementioned windows for the house you are building. Your buddy has just finished the frames part but they cannot be delivered before someone else takes a look and allows them to be merged. This means we can easily communicate, check, upgrade, comment, and update the code before pushing it. No worries then - the frames will not be deployed without checking if that the glass fits. If all is correct, the reviewer checks the sync with master and merges the changes.
Wait! The master might have changed since I have started! I can still be out of sync so I cannot push!
Sure it could have changed and, indeed, it probably has. But why bother? Did anyone change the exact chunk of the code you’re working on? Were any other people working on the frames of the windows at the same time? If so, have a chat with the PM/Scrum Master because it looks like the planning is not going smoothly; then try syncing anyway. I guarantee there will be no problems because the Master is being updated not recreated along the way.
Oh, wait! There is one more thing you can do (and believe me it helps).
Dynamic staging servers!
Each new Branch creates a brand new, dynamic staging environment. This means our QA’s can click through the new feature before it appears on the primary staging. Thank Docker and Pull Request flows for that!
Wrapping up
To sum up, why do we, as PM’s, like it?
- Faster development.
- More deploys to production each sprint as we can push each new feature individually.
- No time wasted on syncing.
- Checking out the results on dynamic staging.
- A clear view of who is working on what.
- Great code quality as we check the commits and the whole Pull Request.
- Less stressed developers (they can hardly break anything!).
- Happy clients, as the work goes smoothly.
- More transparency. Github allows us to see exactly what branches are open, what pull requests were made and who is working on what in real time.















.jpg?width=384&height=202&name=Netguru-Biuro-2018-6425%20(1).jpg)













