Increasing the Accuracy of the Machine Learning Model in the CarLens Mobile App


Welcome to the second part of our journey with CarLens, where we are going through all the methods that we used for improving our Machine Learning model. How did the model’s performance change? Read on to see our results with detailed charts. In case you missed the first one, make sure you read this article too.
CarLens in a nutshell
CarLens is a mobile application for both iOS and Android that lets you recognize cars you find on the street. It uses Augmented Reality and an AI-based solution to detect cars you see through the smartphone camera. Since the initial release in September, Netguru’s machine learning and mobile development teams combined efforts to improve the image recognition technology. And here is the story and lessons learned from the process.
Making sure both platforms process the model identically
When we started working with the ML team, we noticed that there were some differences between how the model behaves on Android and iOS. We needed to investigate the issue, as improving the model itself doesn’t make sense unless it works well in the mobile app. So we first had to make sure it did. We had several things to check:
- Do we perform the conversion to Android and iOS properly?
- Are we sure that the implementation of Tensorflow and CoreML do not have an impact on the effectiveness of the model?
- Are images from the camera processed in exactly the same way on both platforms?
Starting from the simplest
The first idea was to start from the easiest cases. This would be recognizing handwritten digits instead of cars with the help of the popular MNIST dataset.
Even simpler
We switched the model in the app. And shortly after, we realized an even simpler approach would be necessary, as the results were still inconsistent. We needed to create a separate testing application for this purpose. Its aim was to check images instead of processing a real-time camera view! Thus, we could check whether the result on both platforms is the same for the same set of pictures. After verification, the model seemed to be working. But that was not enough – we needed numbers.
Could you go even lower?
We came up with the simplest idea: to generate a model which takes an array of numbers as an input and returns a numeric value as a prediction in its output. This way we made sure that the data is processed identically on all platforms. The results turned out to be the same for iOS, Android, and Python! Great. We could be sure that the conversion was going fine.
Evaluation
We came back to comparing the model for images. We evaluated and tested it. We compared the results in terms of prediction confidence and we encountered another problem with the Android app. The issue was related to the image orientation in the application used for testing. The orientation is not always interpreted right on Android depending on the image source. If you use an image picker, Android ignores the image orientation, but if you choose a picture from a gallery, it sets the image orientation right. Nevertheless, it wasn’t an issue in the CarLens app as long as it's was not an issue for the camera source!
It is worth emphasizing that it is very important to double-check whether you set the image orientation right in the apps on both mobile platforms. It can massively impact the results! Cropping can also have a substantial influence on the result, so make sure you crop your image properly.
Improving the data
The main challenge for most Machine Learning problems is collecting the right data. CarLens was not an exception. It took us a long time to acquire the right dataset. We learned many valuable lessons in the process, and we are ready to share them with you.
Delegating the data collection
If you are not planning on expanding your company in terms of data science, it's better to delegate that task to professionals. They can do it better and faster than you do. There are many companies on the market that can help you with data collection depending on the type of data. In case of pictures, you can reach out to media companies or companies providing crowd workforces.
Web scraping
Web scraping is the most popular way of collecting data you need for training ML models for general-purpose image classification. And we leveraged this method! Our whole team wrote scrapers in Python and learned a lot of new things along the way!
Asking for the help inside
We also asked out our colleagues for help. They sent us the pictures of their cars and some of the photos they already had on their mobile phones. Those photos were of high value since they were taken by a mobile phone camera, which is exactly the kind of device where the data for our final application will come from.
External sources
Additionally, we searched for groups of fans of specific car models on Facebook and asked them for help. Some of them were willing to share pictures of their cars with us. We also asked freelancers to help us, mainly on Fiverr.
Filtering the data
CarLens enables users to recognize cars only from the front. Therefore, we had to filter all the data we collected, which took some time. We built a separate Machine Learning model for this task. However, we still needed to make sure it worked well. So, we also reviewed the pre-filtered data manually. During the whole process, we’ve also come up with an idea to improve the process significantly. We created a custom software for data annotation where we’ve leveraged mobile solutions and created a simple app. We also prepared a bullet-proof process of data management using tools like Quilt and continuous deployment for performing effective experiments with different models’ architecture.
The key takeaway
We can advise from our experience that you establish a data policy before or during the project kickoff. We believe that the most effective ways of data collection are asking professionals for help or using web scraping. These two options would bring the best results compared to the time they require. Also, it is nice to automate things as much as possible. For example, the idea to do automatic labeling with rough estimates from the ML model instead of manually doing it saved us a lot of time!
Changing the approach
Two ML models
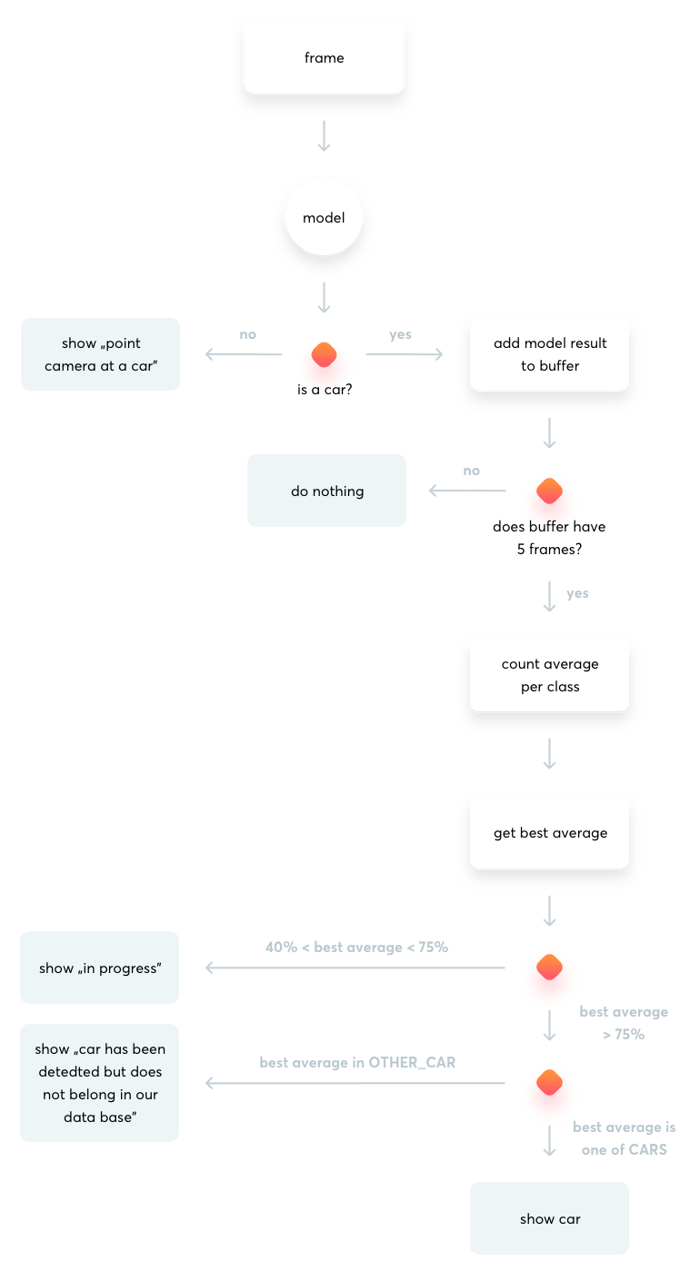
Previously, we had only one model, which returned 7 predictions: 5 car models, and the ‘not a car’ and ‘other car’ classes. Recently, we’ve switched the algorithm and now we use two Machine Learning models: one for car detection (car vs. not a car) and another one for car model recognition (a recognized car model vs. ‘other car’).
Why? Machine Learning models perform better when recognized classes have similar complexity. The recognition of a specific car model requires more details than a simple recognition of whether a car is in the picture or not. Then, we needed to change the classification flow of mobile apps. So, if the first model returned a ‘car’ result, we would send the image to the other model for processing. If not, we would show the ‘not a car’ result to the user and stop there. We also dropped one specific car model, Toyota Corolla, as we saw it was not popular enough on the streets.
Normalization of results
We also added a normalization algorithm to our applications. It normalizes the predictions returned from the model. The algorithm ensures that we will not show the classification result to the user too often. The algorithm can be found in the Github repositories of the projects: iOS and Android.
Results
We created several new models based on the data we obtained. Before feeding the network, the data were augmented in order to increase accuracy. We:
- shifted all images by a random value (moving an image along X and Y axis),
- used horizontal flip (a mirror image of each picture),
- used image rotation (max 10 degrees left and right),
- reduced color RGB channels to grayscale (we re-encoded color pictures into grayscale by a standard algorithm that relied on averaging the red, green, and blue values of each pixel).
We focused on two main models:
- A car detector trained during 20 epochs (an entire dataset passed forward and backward through the neural network once) and built out of 12 convolutional blocks. The model was a binary classifier recognizing car vs not-car classes. Its final test accuracy was 98%.
- Four different types of car classifiers trained during 80 epochs. They recognize four car models and a class labeled “other car”. After a careful evaluation of all four classifiers, we decided to choose the one with recall reaching 90% for all car classes, including other car (which reached 84-85% in the development and test data sets respectively).
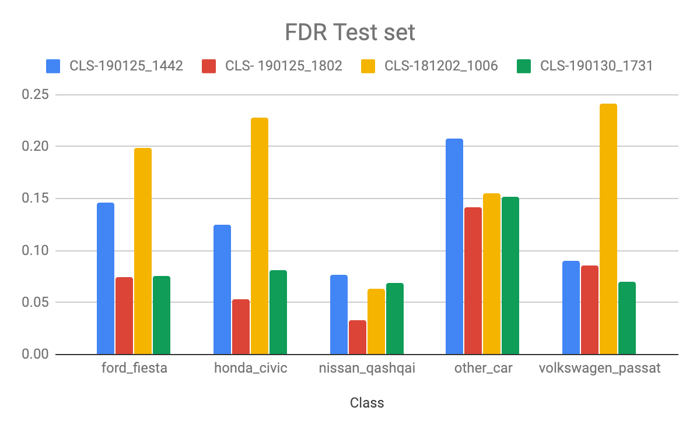
As a measure of performance for the classifier, we used recall and false discovery rate (FDR) – the metrics allowed us to maximize the performance of the classifiers and compare different models. Recall informs us what proportion of actual positives was identified correctly. It is derived from a confusion matrix created after the classification task was performed on our test dataset (for theory and math details, please see: here). FDR on the other hand helps us quantify falsely classified car brands (incorrect classifications). Please see here for more details.
Our goal was to reach at least 90% recall for all classes, including other car. As a result, we selected one model which came closest to the goal. It consists of eighteen convolutional blocks, followed by batch normalization and max pooling layers. The model has 758 665 trainable parameters.
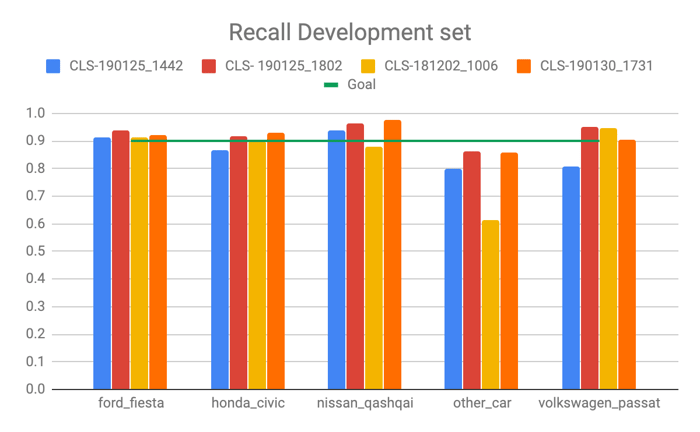
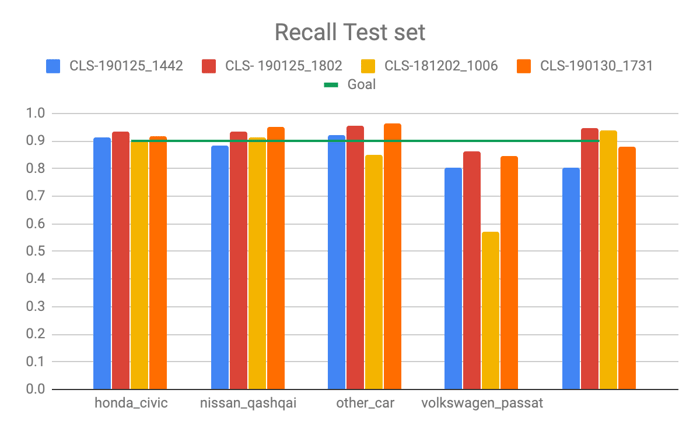
Recall for CLS-190125_1802
|
Goal |
Development set |
Test set |
|
|
ford_fiesta |
0.9 |
0.937 |
0.936 |
|
honda_civic |
0.9 |
0.915 |
0.935 |
|
nissan_qashqai |
0.9 |
0.963 |
0.954 |
|
other_car |
0.9 |
0.860 |
0.862 |
|
volkswagen_passat |
0.9 |
0.953 |
0.945 |
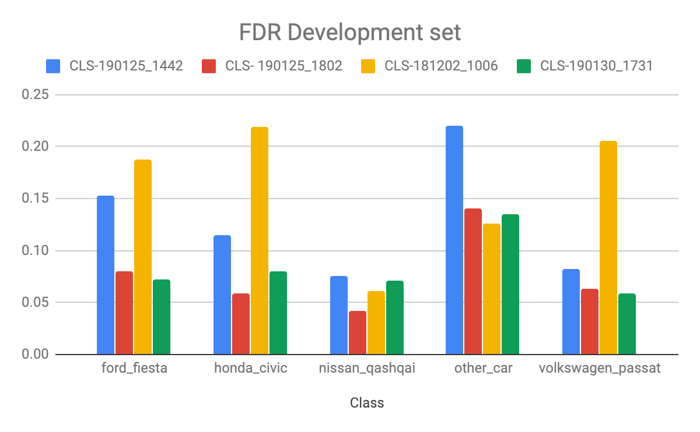
FDR for CLS-190125_1802
|
Development set |
Test set |
||
|
ford_fiesta |
0.08 |
0.07 |
|
|
honda_civic |
0.06 |
0.05 |
|
|
nissan_qashqai |
0.04 |
0.03 |
|
|
other_car |
0.14 |
0.14 |
|
|
volkswagen_passat |
0.06 |
0.09 |
The detector model exhibited very good results and it also helped us a lot in filtering the dataset for classification. As for the classifier, there is still room for improvement. The biggest challenge is to improve the data set for the other_car class.
The classifier tends to make more errors with the “other car” class (relatively high FDR) in comparison to the more homogenic classes that categorize a single car model. The particular brands show very little misclassified examples.
To sum up
Our experience with CarLens taught us that solving Machine Learning problems is not easy. The data is a crucial issue behind a model’s accuracy. We managed to improve our model by:
- Getting the help of experienced ML developers.
- Collecting more data. MUCH more data.
- Dividing one ML model into two separate ones:
- Car Detection model
Predicting whether there is a car in an image or not. - Car Brand Recognition model
Predicting the model of the car in the picture. - Making sure the conversion of the model for iOS and Android was accurate.
- Checking whether iOS and Android apps showed similar results for the same data and the same ML models.
Whoa, a long blogpost, isn't it? So was our journey with CarLens. We would love to hear your feedback! Leave a comment or email us at hi@netguru.com. This is definitely not the last time you’ve heard from us. We are just getting started!
By the way, we are excited to tell you that the CarLensCollectionViewLayout iOS Library has been released! The beautiful animation in CarLens has received lots of attention on our Dribble profile. We decided that we would make it a separate Open Source Library so that you could use it in other projects too!













